
418 L03 Parallel Programming Abstractions
ISPC,3种通信模型(共享内存,消息传递,数据并行)

举例:5way-1shot
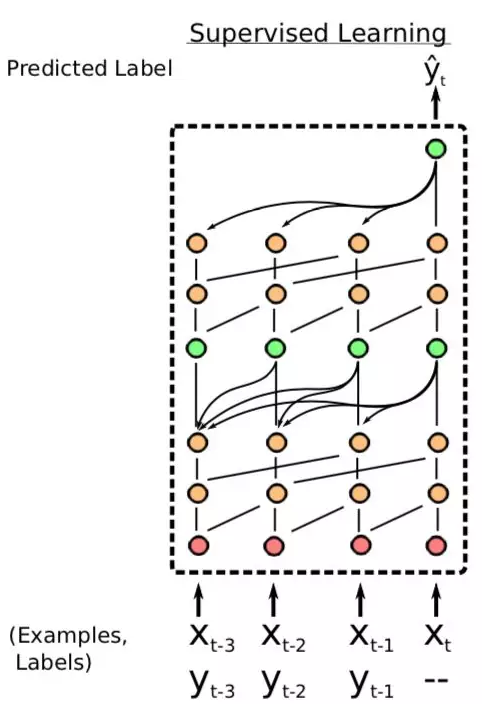
图中包含meta-train和meta-test。每一行称为一个task,每个task包含$D_{train}$和$D_{test}$。$D_{train}$包含5个类,每个类一个样本(即5way-1shot),$D_{test}$由这5个类的新图片构成。
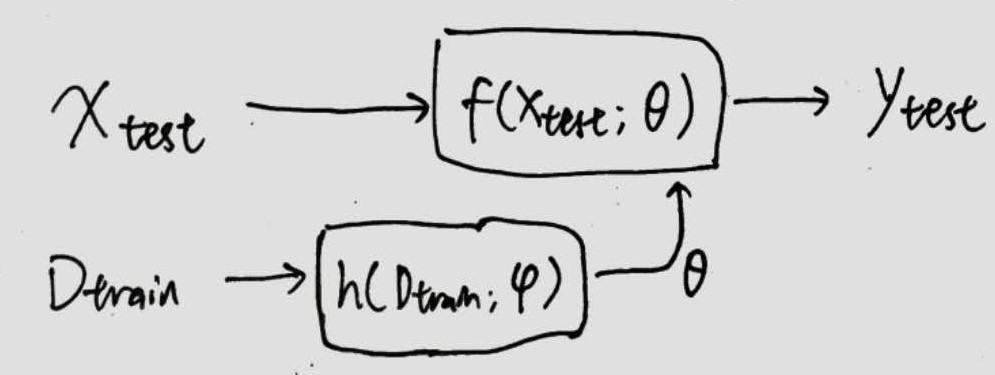
直接利用HyperNetwork生成网络f所需要的参数,这里HyperNetwork起到meta network的作用。训练时使用episodic training,每个episode就是一个task。使用训练集输入到hypernetwork,得到f的参数,然后使用测试集输入到f得到预测的标签,最后用测试集的样本标签得到模型的loss,之后就用梯度下降进行训练,整体是端到端的。
这种方法的缺点是生成参数很麻烦,尤其是当参数空间巨大时。
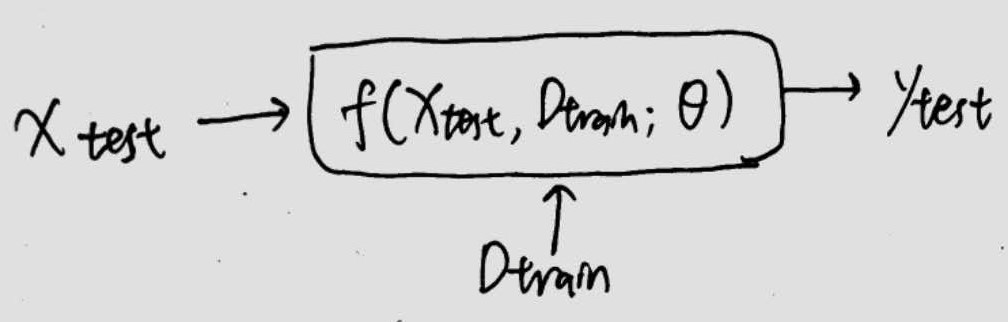
把$D_{train}$当做条件输入到f中,那么这个f本身就变成一个meta network了。f的结构可以是多种多样的,如wavenet的架构等等。
这种方法的缺点是有一个额外的输入作为条件,相比于另外两种不直观。


内循环算法使用$D_{train}$训练神经网络f,得到新的参数$\theta’$,但并不更新参数;外循环利用新参数$\theta’$训练$D_{test}$,但对原参数$\theta$求梯度并更新原参数(将$\theta’$带入最后一步公式会得到二阶导数)。这样操作的目的是,更新参数$\theta$,使得它能最快的找到参数更新方向$\theta’$(有点绕,就这意思=。=)。
这种方法缺点是二层循环计算慢。
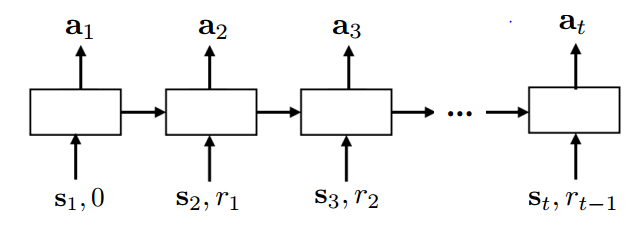
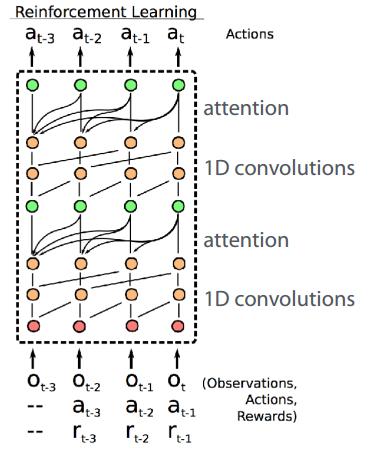
可以使用RNN,attention多重结构
