
December
30th,
2018
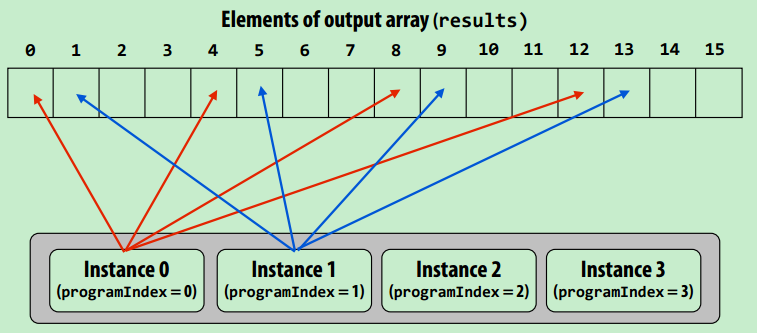

例子:ISPC编程
调用ISPC函数会产生一系列并发执行的实例,ispc编译器产生含SIMD指令的二进制文件(.o)。
SPMD:Single program, multiple data
SIMD:Single instruction, multiple data
关键词
- programCount:同时执行的实例数量
- programIndex:当前实例的id
- uniform:变量修饰符,表示所有实例的变量值相同(注意:uniform和非uniform的变量不能直接进行操作)
- foreach:让编译器自己安排如何并发
内存连续性
注意并发读取数据时,保证数据的内存连续性
export void sinx(
uniform int N,
uniform int terms,
uniform float* x,
uniform float* result)
{
// assumes N % programCount = 0
for (uniform int i=0; i<N; i+=programCount)
{
int idx = i + programIndex;
float value = x[idx];
float numer = x[idx] * x[idx] * x[idx];
uniform int denom = 6;
uniform int sign = -1;
for (uniform int j=1; j<=terms; j++)
{
value += sign * numer / denom;
numer *= x[idx] * x[idx];
denom *= (2*j+2) * (2*j+3);
sign *= -1;
}
result[idx] = value;
}
}
以上例子只是调用ISPC生成一个核上的SIMD指令,当然它也可以用于多核???
并行实例间的通信模型
三种通信模型:程序结构越来越严谨
- 共享内存
- 读写共享变量,同步原语(锁)
- 硬件布局1:SMP(Symmetric multi-processor,如dance-hall结构)
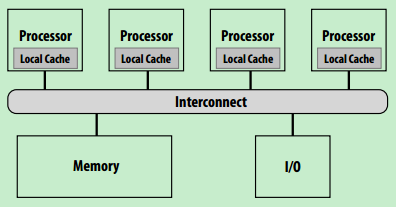
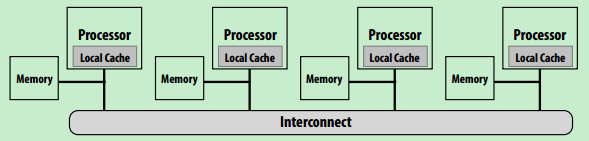
- 硬件布局2,NUMA(Non-uniform memory access)
- 现代处理器常用布局,对于局部内存可以做到低延迟高带宽(类似于缓存机制,很常见√)
- 当处理器很多时,避免处理器与内存间的瓶颈
- 处理器获取不同内存时开销不一致
- 信息传递
- 线程在各自私有的地址空间运行,消息是唯一通信方式
- MPI(message passing interface)
- 不需要额外的硬件实现
- 共享地址空间与消息传递之间并没有明显的界限
- 数据并行
- 对不同数据进行同样操作,形式如map(func, collection),在map结束之后进行同步,比如for_each操作
- stream programming:
- prefetch hide latency;
- 连续映射,避免中间结果的存储,省带宽;
- 用gather、scatter操作处理if…else…
- 常见操作
- 对于一个节点的多核处理器,使用共享内存
- 对于不同节点的通信,使用消息传递