v1.5:基于MPC思想,每执行一步规划就纠正错误。对于小模型鲁棒性较好,在模型不准确时可以很好的控制;计算代价比较大,边规划边收集数据
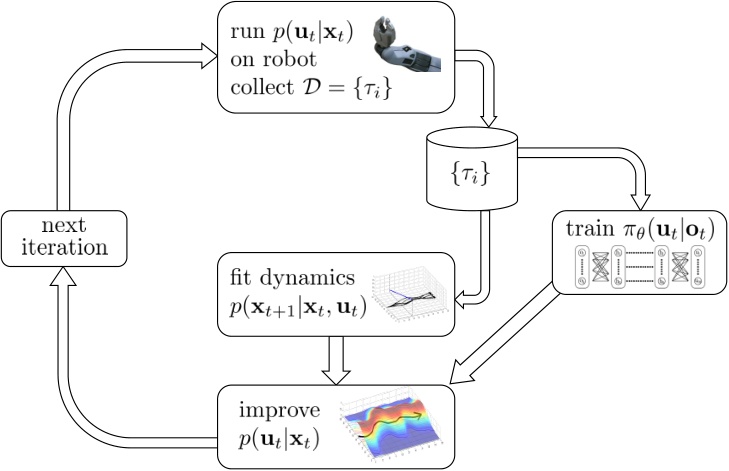
- 运行某种基本策略$\pi_0(\mathbf{a}_t\vert \mathbf{s}_t)$(如随机策略)来收集样本数据$\mathcal{D}=\lbrace(\mathbf{s},\mathbf{a},\mathbf{s}’)_i\rbrace$。
- 通过最小化$\sum_i\Vert f(\mathbf{s}_i,\mathbf{a}_i)-\mathbf{s}_i’\Vert^2$的方法来学习模型动态$f(\mathbf{s},\mathbf{a})$。
- 根据$f(\mathbf{s},\mathbf{a})$来计划未来行动。(如使用iLQR)
- 基于MPC的思想,仅执行计划中的第一步行动,观察到新的状态$\mathbf{s}’$。
- 将这一组新的$(\mathbf{s},\mathbf{a},\mathbf{s}’)$加入到$\mathcal{D}$中。反复执行若干次3-5步之后,回到第2步重新学习模型。
v2.0:使用收益的梯度来优化策略函数。计算代价较小;数值上非常不稳定。
- 运行某种基本策略$\pi_0(\mathbf{a}_t\vert \mathbf{s}_t)$(如随机策略)来收集样本数据$\mathcal{D}=\lbrace(\mathbf{s},\mathbf{a},\mathbf{s}’)_i\rbrace$。
- 通过最小化$\sum_i\Vert f(\mathbf{s}_i,\mathbf{a}_i)-\mathbf{s}_i’\Vert^2$的方法来学习模型动态$f(\mathbf{s},\mathbf{a})$。
- 通过$f(\mathbf{s},\mathbf{a})$,使用反向传播的方法来优化策略函数$\pi_\theta(\mathbf{a}_t\vert \mathbf{s}_t)$。
- 执行$\pi_\theta(\mathbf{a}_t\vert \mathbf{s}_t)$,将新的$(\mathbf{s},\mathbf{a},\mathbf{s}’)$加入到$\mathcal{D}$中。反复执行2-4步。
上一章讨论的主要是v1.5版本的闭环MPC方法,这一篇主要讨论v2.0版本。v2.0有两个优点:1. 计算代价小;2. 策略比模型可能有更好的泛化能力。比如:我们想要打棒球,模型会根据物理条件计算出具体落地点,而实际上人类只是根据经验做出判断。

引导策略搜索 (Guided Policy Search,GPS)
从v2.0的计算图中可以看到,早期的行动会对轨迹产生较大影响,因此梯度偏大,而后期梯度偏小。参考collocation methods,可以将策略引入优化问题中,作为约束条件。问题变成:
对于这个问题,可以分解成普通的轨迹优化和约束$\mathbf{u}_ t=\pi_\theta(\mathbf{x}_t)$的结合。对于轨迹优化,可以使用LQR等方法进行优化。对于约束项,可以使用增广拉格朗日乘子法(augmented Lagrangian method)求解,$\bar{\mathcal{L}}(\mathbf{x},\lambda)=f(\mathbf{x})+\lambda C(\mathbf{x})+\rho\Vert C(\mathbf{x})\Vert^2$,加了一个二次惩罚项,使得在严重违反约束条件时更倾向于控制约束条件以增加稳定性。
记$\tau=(\mathbf{u}_ 1,\ldots,\mathbf{u}_ T,\mathbf{x}_ 1,\ldots,\mathbf{x}_ T)$,则优化问题可以简写为$\min_{\tau,\theta}c(\tau)~\text{s.t.}~\mathbf{u}_ t=\pi_\theta(\mathbf{x}_ t)$,它的增广拉格朗日函数可以写成$\bar{\mathcal{L}}(\tau,\theta,\lambda)=c(\tau)+\sum_{t=1}^T\lambda_t(\pi_\theta(\mathbf{x}_ t)-\mathbf{u}_ t)+\sum_{t=1}^T\rho_t(\pi_\theta(\mathbf{x}_t)-\mathbf{u}_t)^2$,具体算法为:
- 固定$\theta,\lambda$,使用诸如iLQR的方法优化轨迹$\tau\leftarrow\arg\min_\tau\bar{\mathcal{L}}(\tau,\theta,\lambda)$。
- 固定$\tau,\lambda$,使用诸如SGD的方法优化策略参数$\theta\leftarrow\arg\min_\theta\bar{\mathcal{L}}(\tau,\theta,\lambda)$。
- 拉格朗因为日乘子走一个梯度步$\lambda\leftarrow\lambda+\alpha\frac{\mathrm{d}g}{\mathrm{d}\lambda}$。
第一步相当于重新构建一个代价函数,然后执行iLQR。第二步注意到$\theta$只和后两项有关,而后两项的形式简单,且能完全按时间分解:这样的好处是不需要再做反向传播了,而稍作变形,本质上只是一个非常传统的最小二乘监督学习问题,可以用一些SGD方法进行求解,因此整个过程是交替使用轨迹优化和监督学习。这样的方法理论上需要凸性,但是如果没有凸性的话有些时候实践中效果也还可以。
这样的算法属于引导策略搜索(Guided Policy Search,GPS),这样的叫法主要因为策略训练是跟着轨迹优化的结果而来的。一方面,该算法可以被理解成在约束下的轨迹优化算法,同时因为第二步就是一个监督学习过程,另一方面可以被理解成对最优控制的模仿学习。广义的GPS算法的一般结构是这样的:
- 关于某些修改后的代价函数$\tilde{c}(\mathbf{x}_t,\mathbf{u}_t)$进行轨迹分布$p(\tau)$的优化。
- 关于某些监督学习的目标函数优化策略参数$\theta$。
- 修改对偶变量$\lambda$。
随机GPS
由单一策略变成策略分布,问题变成$\min_{p,\theta}c(\tau)~\text{s.t.}~p(\mathbf{u}_ t\vert\mathbf{x}_ t)=\pi_\theta(\mathbf{u}_ t\vert\mathbf{x}_ t)$。和原来方法相比,多了一步用轨迹数据训练策略神经网络的步骤。在论文“End-to-End Training of Deep Visuomotor Policies”中将训练由$\pi_\theta(\mathbf{u}_ t\vert\mathbf{o}_ t)$改成了$\pi_\theta(\mathbf{u}_ t\vert\mathbf{o}_t)$。在训练网络是将输入从状态偷偷替换成原始图像,这样的技巧叫做输入重映射(input remapping trick),有助于我们训练从传感器(如摄像机)直接得到的高维输入的策略。
PLATO算法
DAgger算法:
- 从人工数据集$D$训练出策略$p_{\pi_{\theta}}(o_t)$
- 运行策略$p_{\pi_{\theta}}(o_t)$获得新数据集$D_{\pi}$(电脑控制汽车行驶,并收集图片)
- 人工对数据集进行标注,得到新的$(o_t,a_t)$(注:此处为人工生成$a_t$,而非机器生成$a_t$,相当于人对机器进行纠正)
- 合并数据集$\mathcal{D}\leftarrow\mathcal{D}\cup\mathcal{D}_{\pi}$
PLATO(Policy Learning using Adaptive Trajectory Optimization)是针对DAgger算法的改进。DAgger算法在第2步运行策略$\pi_\theta(\mathbf{u}_ t\vert\mathbf{o}_ t)$来获取数据集,但这里初始策略可能很糟糕,只有在反复增加数据之后才能缓解分布不匹配的问题。PLATO将MPC思想引入到DAgger算法中,做一点妥协来得到收敛性保证。新的近似策略为$\hat{\pi}(\mathbf{u}_ t\vert\mathbf{x}_ t)=\mathcal{N}(\mathbf{K}_ t\mathbf{x}_ t+\mathbf{k}_ t,\Sigma_{\mathbf{u}_ t})$,由使用LRQ求解$\hat{\pi}(\mathbf{u}_ t\vert\mathbf{x}_ t)=\arg\min_{\hat{\pi}}\sum_{t’=t}^T\mathbf{E}_ {\hat{\pi}}[c(\mathbf{x}_ {t’},\mathbf{u}_ {t’})]+\lambda D_{\text{KL}}(\hat{\pi}(\mathbf{u}_ t\vert\mathbf{x}_ t)\Vert\pi_\theta(\mathbf{u}_t\vert\mathbf{o}_t))$得到。这个策略是一个线性均值的高斯分布,以降低代价函数为目标,同时也保证新策略与原策略差别不大。
总结
样本效率
由低到高,每两级之间差10倍
- gradient-free methods:无模型,比计算梯度,依赖于随机优化。如NES(Natural Evolution Strategies),CMA-ES
- fully online methods:on-policy算法,依赖大规模并行。如A3C
- policy gradient methods:on-policy,使用批量数据。如TRPO
- replay buffer value estimation methods:off-policy。如Q学习,DDPG,NAF
- model-based deep RL:如GPS
- model-based “shallow” RL:不使用深度神经网络。如PILCO
具体算法选择
- 是否能从模拟器中学习,决定了样本效率
- 模拟成本与训练成本的比重