
December
28th,
2018

并行执行(parallel execution),增加硬件使更快
程序执行可以简化为3个步骤,解码、执行、寄存器更新(L1 cache)。
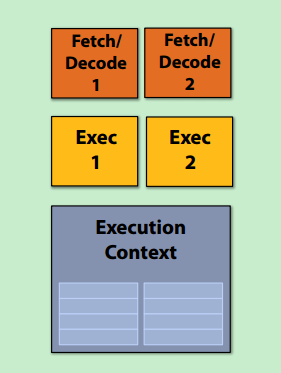
1. superscalar
在一颗处理器内核中执行指令级并行instruction level parallelism (ILP),因为存在多个解码、执行单元。
现代CPU的并行:
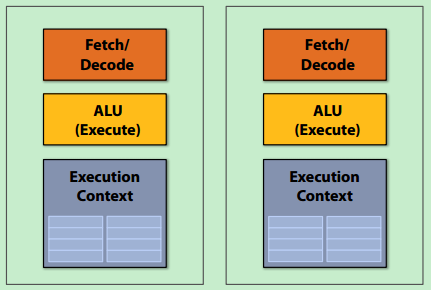
2. 更多的核
每颗核可能变慢,但整体更快。提供线程级别的并行,每个核完成不同的指令流;软件创建线程。
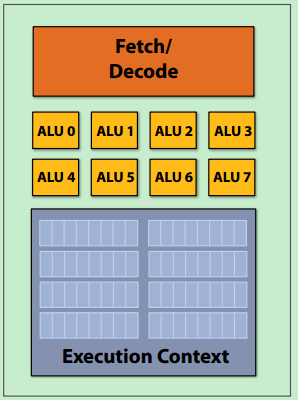
3. SIMD(Single instruction, multiple data)
每个核有多个ALU,可以同时执行多个相同指令,实现数据并行。
- mask问题:最坏情况:在分支中,每次if和else比例均是1:7,且if需要更多的ALU时。
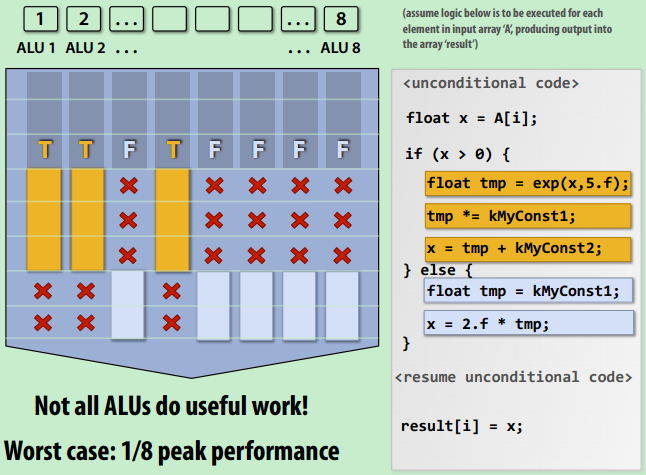
- 术语:指令流一致性(Instruction stream coherence,coherent execution)。即多个指令流有相同的指令,可以使用SIMD进行并行。与缓存一致性区分。
- explicit SIMD:由编译器产生可并行的指令,需要程序员调用内联函数(SSE,AVX),或少数编译器也可以通过分析循环依赖性进行优化
- implicit SIMD(GPU):由硬件选择N个实例同时执行
内存获取(accessing memory),充分利用已有硬件使高效
- 延迟与带宽:延迟表示从请求到获取的时间差,带宽表示每秒可获得的最大数据
- stall:由于指令依赖性导致无法执行下一条指令,主要由于内存引起,可以用Memory access times来描述延迟。
- 缓存(reduce latency):对于在缓存中的数据,处理器可以实现充分的并行。
- prefetch(hide latency):DMA挑选部分数据读入缓存,有时也会带来缓存污染等等问题。
- 多线程并发(hide latency):同一核上交替运行线程,划分L1缓存支持更多线程,每个线程充分利用ALU。
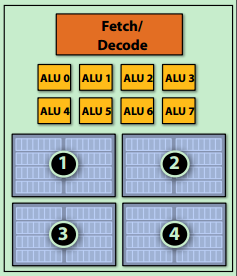
- *hyper threading = superscalar + multi-threading
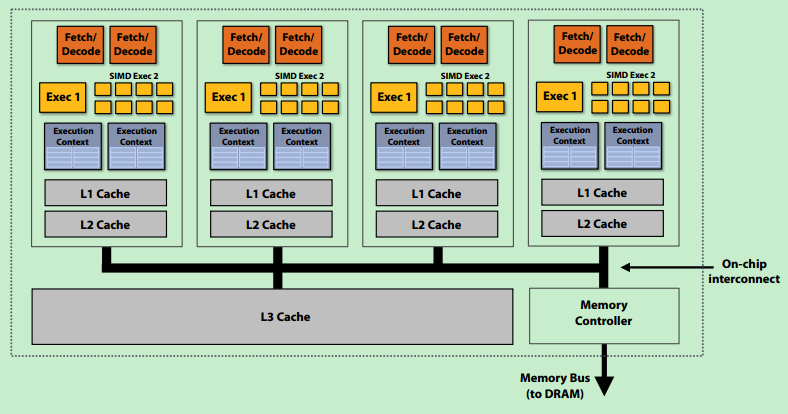
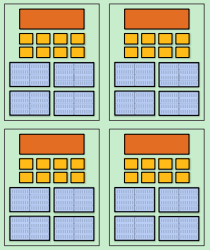
- 例子:4核,8 SIMD ALUs/核,4线程/核 ==> 4指令流,16并发指令流,128条运算
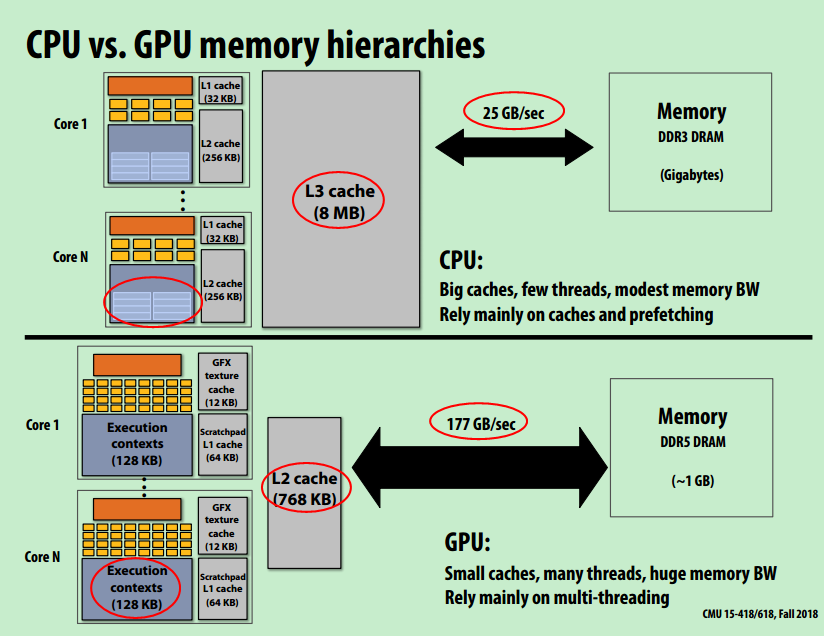
- CPU VS GPU:CPU更大缓存,更小带宽。
总结:现代CPU架构