c++ primer note
c++ primer note
class TreeNode(object):
def __init__(self, x):
self.val = x
self.left = None
self.right = None
def listToTreeNode(inputValues):
root = TreeNode(inputValues[0])
nodeQueue = [root]
front = 0
index = 1
while index < len(inputValues):
node = nodeQueue[front]
front = front + 1
item = inputValues[index]
index = index + 1
if item != None:
leftNumber = item
node.left = TreeNode(leftNumber)
nodeQueue.append(node.left)
if index >= len(inputValues):
break
item = inputValues[index]
index = index + 1
if item != None:
rightNumber = item
node.right = TreeNode(rightNumber)
nodeQueue.append(node.right)
return root
def printTree(root):
if not root:
return []
queue = []
queue.append(root)
ret = []
while len(queue):
for i in range(len(queue)):
res = []
curNode = queue.pop(0)
res.append(curNode.val)
if curNode.left:
queue.append(curNode.left)
res.append(curNode.left.val)
else:
res.append('None')
if curNode.right:
queue.append(curNode.right)
res.append(curNode.right.val)
else:
res.append('None')
ret.append(res)
for item in ret:
print '{} -> {}, {}'.format(*item)
if __name__ == "__main__":
a = [1, 2, 3, 4, None, 6, None]
root = listToTreeNode(a)
printTree(root)
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}
public class Solution {
public static TreeNode listToTreeNode(String input) {
String[] parts = input.split(",");
String item = parts[0];
TreeNode root = new TreeNode(Integer.parseInt(item));
Queue<TreeNode> nodeQueue = new LinkedList<>();
nodeQueue.add(root);
int index = 1;
while(!nodeQueue.isEmpty()) {
TreeNode node = nodeQueue.remove();
if (index == parts.length)
break;
item = parts[index++];
item = item.trim();
if (!item.equals("null")) {
int leftNumber = Integer.parseInt(item);
node.left = new TreeNode(leftNumber);
nodeQueue.add(node.left);
}
if (index == parts.length)
break;
item = parts[index++];
item = item.trim();
if (!item.equals("null")) {
int rightNumber = Integer.parseInt(item);
node.right = new TreeNode(rightNumber);
nodeQueue.add(node.right);
}
}
return root;
}
public static void printTree(TreeNode root){
if(root == null)
return;
LinkedList<TreeNode> queue = new LinkedList<>();
queue.add(root);
List<List<String>> ret = new LinkedList<>();
while(!queue.isEmpty()){
for(int i = 0; i < queue.size(); i++){
ArrayList<String > res = new ArrayList<>();
TreeNode curNode = queue.removeFirst();
res.add(String.valueOf(curNode.val));
if(curNode.left != null) {
queue.add(curNode.left);
res.add(String.valueOf(curNode.left.val));
} else
res.add("null");
if(curNode.right != null) {
queue.add(curNode.right);
res.add(String.valueOf(curNode.right.val));
} else
res.add("null");
ret.add(res);
}
}
for(List<String> item: ret)
System.out.printf("%s -> %s, %s\n", item.get(0), item.get(1), item.get(2));
}
public static void main(String[] args) {
Solution s = new Solution();
TreeNode root = s.listToTreeNode(new String("1,2,3,4,null,6,null"));
printTree(root);
}
}
class BasicMatrixMath{
private int mod = 1000000007;
public long[][] add(long[][] matrixa, long[][] matrixb) {
for(int i = 0; i < matrixa.length; i++)
for(int j = 0; j < matrixa[0].length; j++) {
matrixa[i][j] = matrixa[i][j] + matrixb[i][j];
matrixa[i][j] %= mod;
}
return matrixa;
}
public long[][] sub(long[][] matrixa, long[][] matrixb) {
for(int i=0; i<matrixa.length; i++)
for(int j=0; j<matrixa[0].length; j++) {
matrixa[i][j] = matrixa[i][j] - matrixb[i][j];
matrixa[i][j] %= mod;
}
return matrixa;
}
public long[][] mul(long[][] matrixa, long[][] matrixb) {
long[][] result = new long[matrixa.length][matrixb[0].length];
for(int i = 0; i < matrixa.length; i++) {
for(int j = 0; j < matrixb[0].length; j++) {
result[i][j] = 0;
for (int k = 0; k < matrixa[0].length; k++) {
result[i][j] += matrixa[i][k] * matrixb[k][j];
result[i][j] %= mod;
}
}
}
return result;
}
public long[][] power(long[][] a, int n){
if(n == 1)
return a;
long[][] c;
long[][] b = power(a, n/2);
c = mul(b, b);
if(n % 2 == 0)
return c;
else{
b = mul(c, a);
return b;
}
}
}
递推式:
进行矩阵变换:
用矩阵幂运算由$O(n)$加速到$O(log(n))$
Keyphrases:
Seq2Seq and Attention Mechanisms, Neural Machine Translation, Speech Processing
The encoder network’s job is to read the input sequence to our Seq2Seq model and generate a fixed-dimensional context vector C for the sequence.
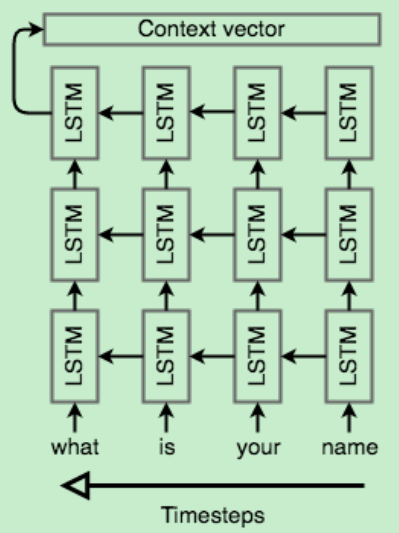
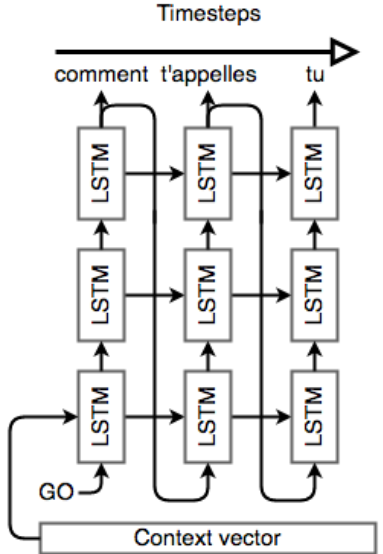
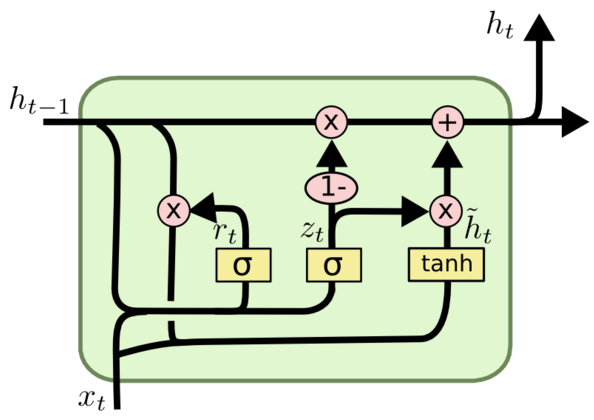
we simply add another cell but feed inputs to it in the opposite direction.
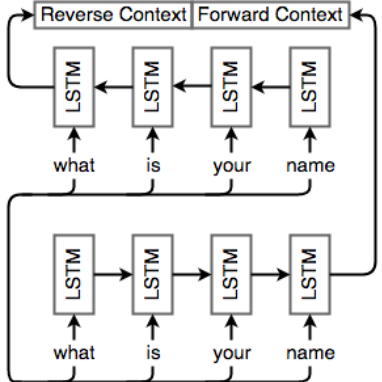
Attention mechanisms make use of this observation by providing the decoder network with a look at the entire input sequence at every decoding step; the decoder can then decide what input words are important at any point in time.
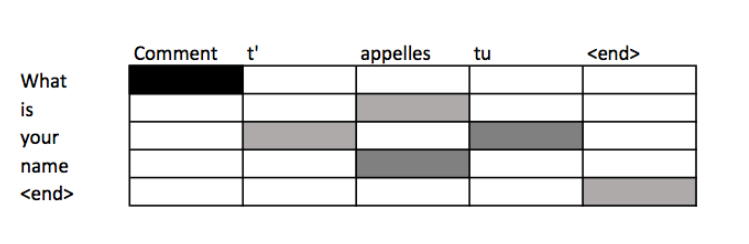
scores $\alpha_{i,j}$ at decoding step i signify the words in the source sentence that align with word i in the target.we can use attention scores to build an alignment table – a table mapping words in the source to corresponding words in the target sentence.
This model can efficiently translate long sentences.
Another approach to machine translation comes from statistical machine translation. Consider a model that computes the probability $P(\bar{s}\mid s)$ of a translation $\bar{s}$ given the original sentence $s$.we want
As the search space can be huge, we need to shrink its size.
Beam search: the idea is to maintain K candidates at each time step.
and compute $H_{t+1}$ by expanding $H_t$ and keeping the best $K$ candidates.

Let $p_n$ denote matched n-grams,$w_n=1/2^n$be a geometric weighting for the precision of the n’th gram.Our brevity penalty is defined as
where $len_{ref}$ is the length of the reference translation and $len_{MT}$ is the length of the machine translation.
The BLEU score is then defined as
Softmax can be quite expensive to compute with a large vocabulary and its complexity also scales proportionally to the vocabulary size.
They only save computation during training step.
Partitioning the training data into subsets with t unique target words.This concept is very similar to NCE.However, the main difference is that these negative samples are sampled from a biased distribution Q for each subset V’ where
The final prediction is either the word $y_t^w$ chosen by softmax over candidate list, as in previous methods, or $y_t^l$ copied from source text.
It deal with rare or unknown words.
Representing rare and unknown words as a sequence of subword units.
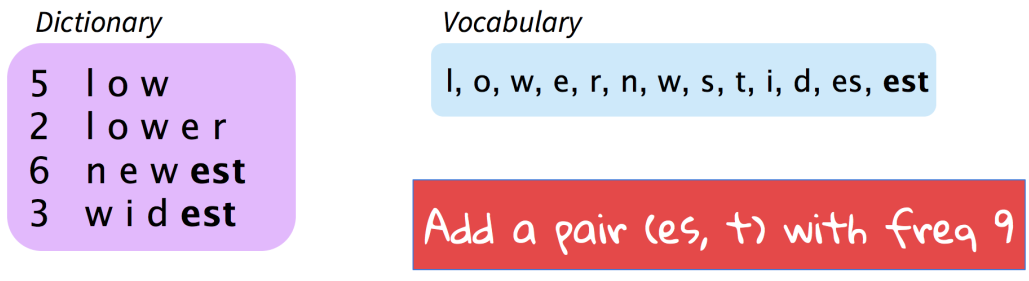
One can choose to either build separate vocabularies for training and test sets or build one vocabulary jointly.
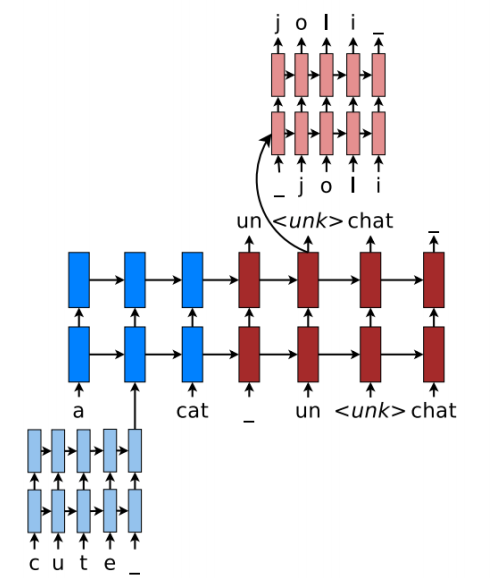
Word-based Translation as a Backbone: The core of the hybrid NMT is a deep LSTM encoder-decoder that translates at the word level.
Source Character-based Representation: We learn a deep LSTM model over characters of rare words, and use the final hidden state of the LSTM as the representation for the rare word.
Target Character-level Generation: The solution is to have a separate deep LSTM that “translates” at the character level given the current word-level state.The system is trained such that whenever the wordlevel NMT produces an $\langle unk\rangle$, the character-level decoder is asked to recover the correct surface form of the unknown target word.
Keyphrases:
Language Models. RNN. Bi-directional RNN. Deep RNN. GRU. LSTM.
Language models compute the probability of occurrence of a number of words in a particular sequence.
In some cases, the window of past consecutive n words may not be sufficient to capture the context.Bengio et al. introduced the first large-scale deep learning for natural language processing model that enables capturing this type of context via learning a distributed representation of words.
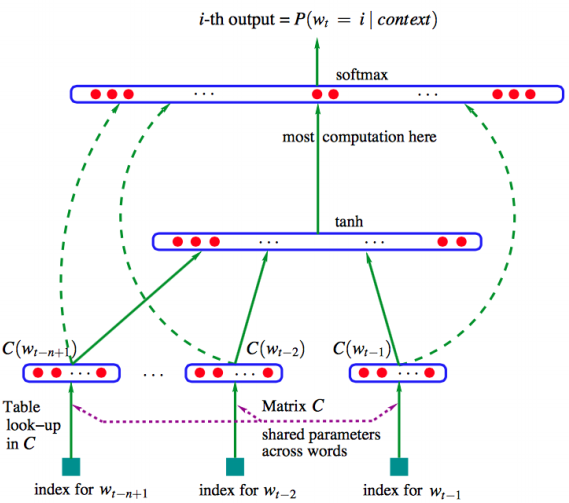
In all conventional language models, the memory requirements of the system grows exponentially with the window size n making it nearly impossible to model large word windows without running out of memory.
Recurrent Neural Networks (RNN) are capable of conditioning the model on all previous words in the corpus.
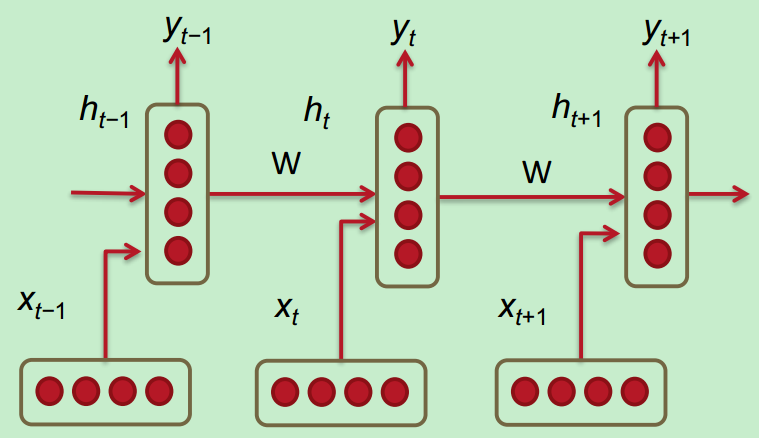
Below are the details associated with each parameter in the network:
The loss function used in RNNs is often the cross entropy error.
Perplexity relationship; it is basically 2 to the power of the negative log probability of the cross entropy error.Perplexity is a measure of confusion where lower values imply more confidence in predicting the next word in the sequence.
The amount of memory required to run a layer of RNN is proportional to the number of words in the corpus.
To make predictions based on future words by having the RNN model read through the corpus backwards
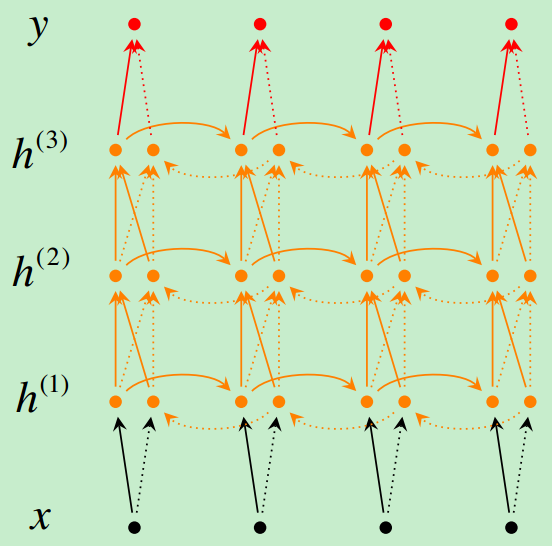
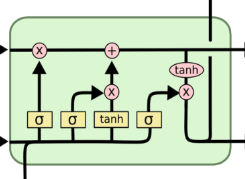
Although RNNs can theoretically capture long-term dependencies, they are very hard to actually train to do this. Gated recurrent units are designed in a manner to have more persistent memory thereby making it easier for RNNs to capture long-term dependencies.