Keyphrases:
Seq2Seq and Attention Mechanisms, Neural Machine Translation, Speech Processing
Neural Machine Translation with Seq2Seq
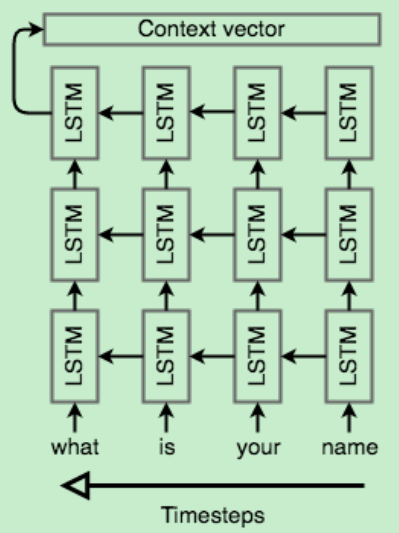
encoder
The encoder network’s job is to read the input sequence to our Seq2Seq model and generate a fixed-dimensional context vector C for the sequence.
- LSTM or stacked LSTM: compress an arbitrary-length sequence into a single fixed-size vector.
- process the input sequence in reverse
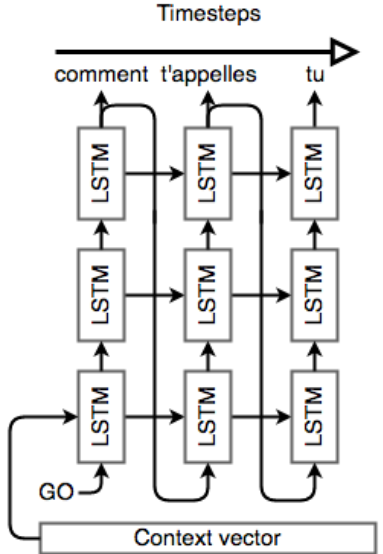
decoder
- Initialize the hidden state of our first layer with the context vector from above.
- pass in a special token to signify the start of output generation.
- pass that output word into the first layer, and repeat the generation.
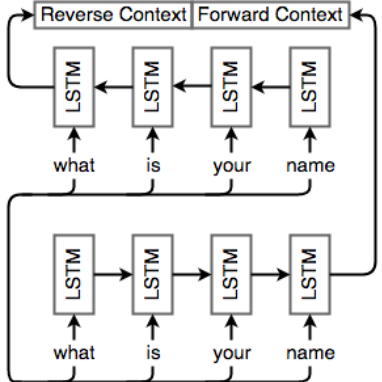
Bidirectional RNNs
we simply add another cell but feed inputs to it in the opposite direction.
Attention Mechanism
Attention mechanisms make use of this observation by providing the decoder network with a look at the entire input sequence at every decoding step; the decoder can then decide what input words are important at any point in time.
- $h_i$: hidden vectors representing the input sentence.
- $s_i$: hidden vectors representing the output sentence.
- $y_i$: generated word
- $c_i$: context vector that capture the context from the original sentence that is relevant to the time step i of the decoder.
scores $\alpha_{i,j}$ at decoding step i signify the words in the source sentence that align with word i in the target.we can use attention scores to build an alignment table – a table mapping words in the source to corresponding words in the target sentence.
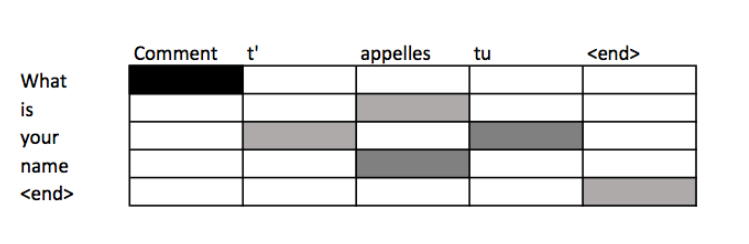
This model can efficiently translate long sentences.
Sequence model decoders
Another approach to machine translation comes from statistical machine translation. Consider a model that computes the probability $P(\bar{s}\mid s)$ of a translation $\bar{s}$ given the original sentence $s$.we want
As the search space can be huge, we need to shrink its size.
Beam search: the idea is to maintain K candidates at each time step.
and compute $H_{t+1}$ by expanding $H_t$ and keeping the best $K$ candidates.

Evaluation of Machine Translation Systems
Bilingual Evaluation Understudy (BLEU)
Let $p_n$ denote matched n-grams,$w_n=1/2^n$be a geometric weighting for the precision of the n’th gram.Our brevity penalty is defined as
where $len_{ref}$ is the length of the reference translation and $len_{MT}$ is the length of the machine translation.
The BLEU score is then defined as
Dealing with the large output vocabulary
Softmax can be quite expensive to compute with a large vocabulary and its complexity also scales proportionally to the vocabulary size.
Scaling softmax
- Noise Contrastive Estimation: randomly sampling K words from negative samples.
- Hierarchical Softmax
They only save computation during training step.
Reducing vocabulary
Partitioning the training data into subsets with t unique target words.This concept is very similar to NCE.However, the main difference is that these negative samples are sampled from a biased distribution Q for each subset V’ where
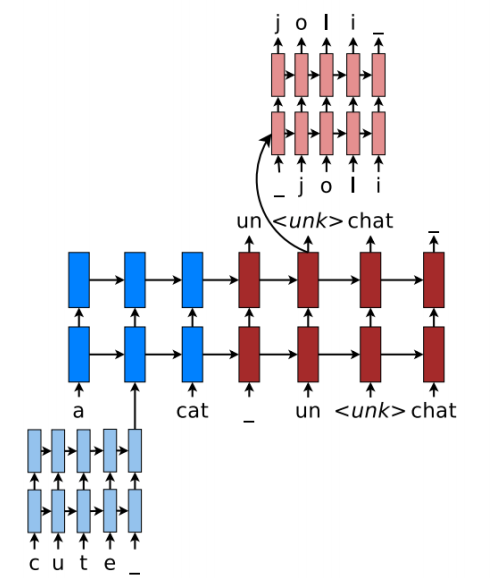
Handling unknown words
The final prediction is either the word $y_t^w$ chosen by softmax over candidate list, as in previous methods, or $y_t^l$ copied from source text.
Word and character-based models
It deal with rare or unknown words.
Word segmentation
Representing rare and unknown words as a sequence of subword units.
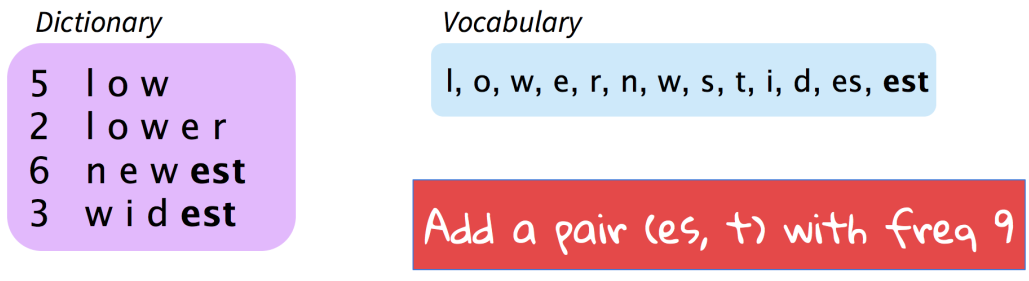
One can choose to either build separate vocabularies for training and test sets or build one vocabulary jointly.
Hybrid NMT
Word-based Translation as a Backbone: The core of the hybrid NMT is a deep LSTM encoder-decoder that translates at the word level.
Source Character-based Representation: We learn a deep LSTM model over characters of rare words, and use the final hidden state of the LSTM as the representation for the rare word.
Target Character-level Generation: The solution is to have a separate deep LSTM that “translates” at the character level given the current word-level state.The system is trained such that whenever the wordlevel NMT produces an $\langle unk\rangle$, the character-level decoder is asked to recover the correct surface form of the unknown target word.