
January
4th,
2019

目标:
- 负载均衡(本节)
- 减少由并行带来的额外工作overhead(本节)
- 减少通信成本
负载均衡
所有处理器同时起步、同时结束
任务分配方式
- static:可预计任务时间和数量
- semi-static:短期内可预计任务时间和数量,阶段性调整任务安排
- dynamic:不可预计任务时间和数量,使用共享工作队列(线程池)
动态任务分配
单一队列
- 任务颗粒度:任务过小时,任务间切换时间(或lock等待时间)过长,导致整体性能下降;可以增加颗粒度,让一个任务串行执行一系列任务。

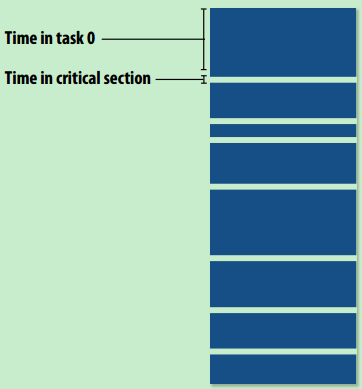
- 任务数量的权衡:任务数量增加,导致颗粒度减小,但能使动态分配负载更均衡。
- 长任务:先安排,需要关于负载的预测
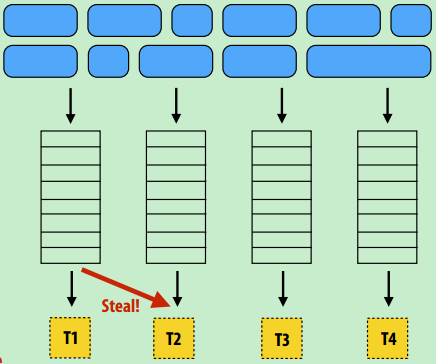
分布式队列(简单介绍)
- 定义:每个线程对应一个队列,线程从自己的队列里取任务,或者从其他队列里“偷”(当队列为空)
- 优点:避免多个线程访问单一队列的同步锁问题
- 额外问题:
- “偷”时引起额外的同步、通信,引起负载不均衡,只在必要时进行
- 局部性:自己产生-消费
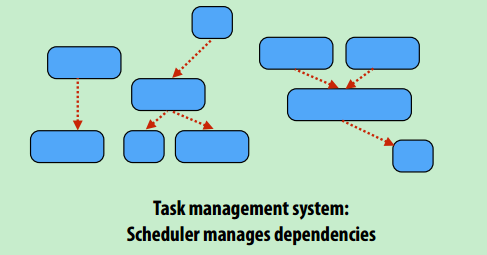
队列中任务可以存在依赖性,只有所有依赖条件被满足,任务才能被取出(CUDA可以设置依赖性??)
foo_handle = enqueue_task(foo); // enqueue task foo (independent of all prior tasks)
bar_handle = enqueue_task(bar, foo_handle); // enqueue task bar, cannot run until foo is complete
fork-join并行模式
cilk-plus:C++语言拓展,GCC、Intel ICC支持
基本用法
- cilk_spawn:实例与主程序异步执行
- cilk_sync:等待所有展开实例结束
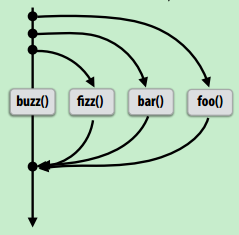
cilk_spawn foo();
cilk_spawn bar();
cilk_spawn fizz();
buzz();
cilk_sync;
例子:并行快排
void quick_sort(int* begin, int* end) {
if (begin >= end - PARALLEL_CUTOFF)
std::sort(begin, end);
else {
int* middle = partition(begin, end);
cilk_spawn quick_sort(begin, middle);
quick_sort(middle+1, last);
}
}
内部实现
- pthread实现
- 用pthread_create实现存在的问题:
- 展开操作开销大
- 过多的实例(远大于核数,很多并发线程,导致上下文切换开销,缺少缓存局部性)
- 实际实现
- 线程池,在第一次展开时创建所有线程
- 用pthread_create实现存在的问题:
- 基本队列结构
- 队列中任务顺序:子任务放底部(优先处理),当前任务放顶部(供“偷取”),原因见下一条
- 双端队列,当前线程从底部取任务,其他线程从顶部取任务(1. 当前线程和其他“偷取”线程不会同时操作队列中的相同元素;2. 队列顶部任务处于递归树的顶部,是“大”任务,需要优先处理;3. 最大化局部性,让当前线程优先处理当前队列中任务)
- 任意性:空闲线程从任意线程队列“偷取”任务
- 贪婪性:任意队列为空,线程就会“偷取”,而不是等待
- cilk_sync结束时同步信号
- 不存在“偷取”时,可以直接结束,不需要同步
- 每次出现“偷取”时,会记录有多少偷取,已完成多少,当“偷取”等于已完成时,表示整个流程结束
利用子任务优先处理的机制,写更高效的代码
for (int i=0; i<N; i++) {
cilk_spawn foo(i);
}
cilk_sync;
// 并行生成子任务
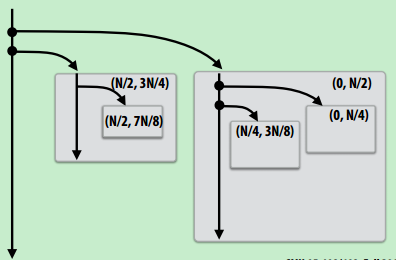
void recursive_for(int start, int end) {
while (start <= end - GRANULARITY){
int mid = (end - start) / 2;
cilk_spawn recursive_for(start, mid);
start = mid;
}
for (int i=start; i<end; i++)
foo(i);
}
recursive_for(0, N);