
January
8th,
2019

目标:
- 负载均衡
- 减少由并行带来的额外工作overhead
- 减少通信成本(本节)
消息传递
阻塞模式
- send:在sender接收到receiver发出的ack信号后,函数得到返回值
- recv:在receiver接收到数据并返回ack信号后,函数得到返回值
- 可能存在循环等待导致死锁,需要特殊改进,如分奇偶依次进行,或改成非阻塞
非阻塞模式
- send:另一个线程异步等待数据并发送;当前线程立即返回,可以在未来调用 CHECKSEND检查数据是否发送,且无法操纵数据缓存区??
- recv:另一个线程异步等待接收数据;当前线程立即返回,可以在未来调用CHECKRECV检查数据是否接收
延迟与带宽
- 延迟latency:完成传输需要的时间
- 带宽bandwidth:单位时间传输的数据量
- 增加带宽:减少延迟,更多通道,流水线
通信模型
例子:发送n-bit信息的通信时间
非流水线模型
$T(n) = T_0+\frac{n}{B}$
- $T(n)$:总通信时间
- $T_0$:启动时间,第一bit到目的地时间
- $n$:通信字节数
- $B$:通信速率(带宽)
- 有效带宽:$n/T(n)$
流水线模型
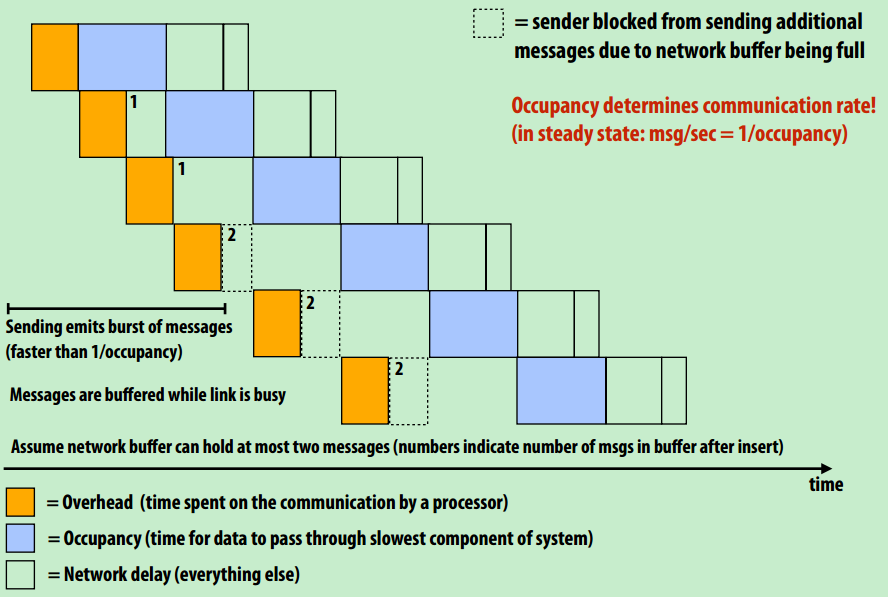
总通信时间=overhead(处理器通信)+occupancy(数据传输)+network delay(其他)
- 紫色部分表示数据传输,会依次进行
- 黄色部分表示处理器通信,先依次进行,当数据缓冲区饱和,就会增加处理检核
通信成本
成本分类
- inherent:
- 必不可少的通信成本
- 通信-计算比例越低,并行效率越高
- 好的任务分配方案能有效减少这部分通信成本

- Artifactual
- 其他通信成本
- 如:分布式集群中数据分布太差,数据并没有在经常调用它的处理器周围
- 如:有限的缓存,导致载入数据时不能一次性载入,需重复加载
补充:cache miss
- cold miss:第一次使用时
- capacity miss:工作集大于缓存容量
- conflict miss:不同块由于index相同而互相替换
- communication miss:两台处理器指向同一块内存,其中一台在自己的区域进行了缓存,另一台又缓存一次
减少通信成本
- 时间局部性:合并for循环
// 3 load,1 save,3 cal,比起分开来写load/save更少 for (int i=0; i<n; i++) E[i] = D[i] + (A[i] + B[i]) * C[i]; - 空间局部性:缓存连续性
- 共享数据:操作同一块数据的线程同时执行,例如CUDA thread
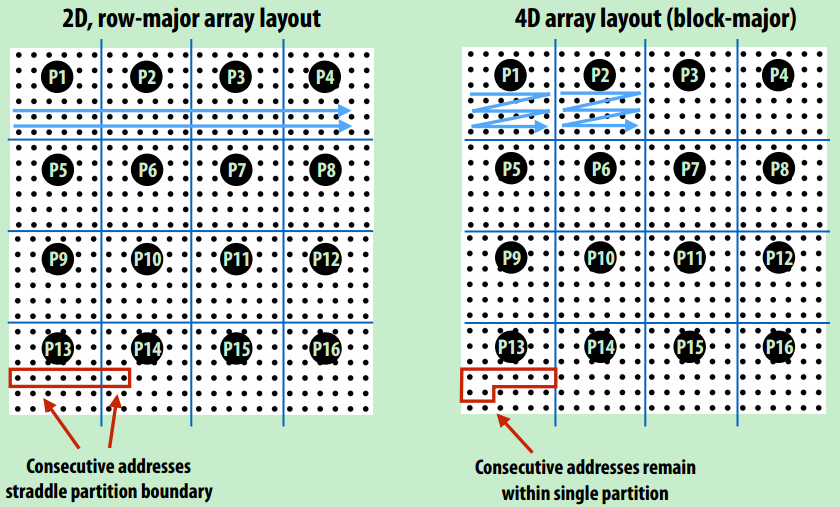
- 块状数据存储
- 任务分配均是块状
- 内存布局只有右边是块状
冲突
- 定义:当一个资源存在多个请求时,存在冲突
- 分类
- 多对一:高冲突,低延迟,例CUDA shared memory
- 树状:低冲突,高延迟,例动态任务分配中分布式队列
