
January
3rd,
2019

GPU基本结构
多核芯片+单核SIMD+单核多线程并发。
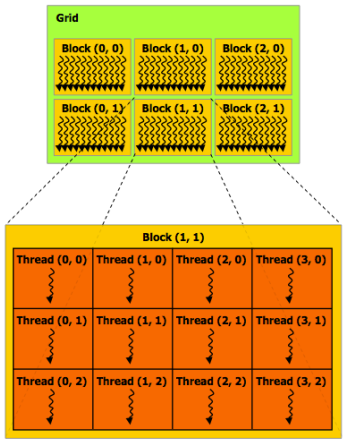
CUDA:Grid ==> Block ==> Thread(并发)
// host code
const int Nx = 11;
const int Ny = 5;
dim3 threadsPerBlock(4, 3, 1);
dim3 numBlocks((Nx+threadsPerBlock.x-1)/threadsPerBlock.x,
(Ny+threadsPerBlock.y-1)/threadsPerBlock.y, 1);
matrixAddDoubleB<<<numBlocks, threadsPerBlock>>>(A, B, C);
// device code
__device__ float doubleValue(float x)
{
return 2 * x;
}
// kernel definition
__global__ void matrixAddDoubleB(float A[Ny][Nx],
float B[Ny][Nx],
float C[Ny][Nx])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < Nx && j < Ny)
C[j][i] = A[j][i] + B[j][i];
}
显存模型
内存与显存的映射
float* A = new float[N];
int bytes = sizeof(float) * N;
float* deviceA; // 指向显存,无法解引用
cudaMalloc(&deviceA, bytes);
cudaMemcpy(deviceA, A, bytes, cudaMemcpyHostToDevice);
显存分类
- device global memory
- block shared memory:该block内线程共享,更快,谨慎使用
- thread memory:每个线程私有
例子:一维卷积
// host code
int N = 1024 * 1024
cudaMalloc(&devInput, sizeof(float) * (N+2) ); // global memory
cudaMalloc(&devOutput, sizeof(float) * N); // global memory
convolve<<<N/THREADS_PER_BLK, THREADS_PER_BLK>>>(N, devInput, devOutput);
// kernel code version 1
__global__ void convolve(int N, float* input, float* output) {
int index = blockIdx.x * blockDim.x + threadIdx.x;
float result = 0.0f;
// 每个线程从global memory读3次
for (int i=0; i<3; i++)
result += input[index + i];
output[index] = result / 3.f;
}
// kernel code version 2
__global__ void convolve(int N, float* input, float* output) {
__shared__ float support[THREADS_PER_BLK+2]; // shared memory
int index = blockIdx.x * blockDim.x + threadIdx.x;
// 1.从global memory载入至shared memory
support[threadIdx.x] = input[index];
if (threadIdx.x < 2) {
support[THREADS_PER_BLK + threadIdx.x] = input[index+THREADS_PER_BLK];
}
// 2.同步,类似于block barrier
__syncthreads();
// 3.从shared memory读写,平均每个线程从global memory读1次,从shared memory读3次
float result = 0.0f;
for (int i=0; i<3; i++)
result += support[threadIdx.x + i];
output[index] = result / 3.f;
}
CUDA同步方法
- __syncthreads(),同步block内所有线程
- 原子操作:atomicADD
其他
block调度
GPU由硬件实现block的调度,每个block在完成任务后接收下一个任务。block之间无依赖性,block之间无法同步。
另一种模式:worker pool(如线程池),提前分配好所有worker(数量足够以至于能隐藏IO延迟)所需资源,并将任务动态分配给每个worker
warp
GPU硬件单元,同一个block(同指令)中选择32个thread作为warp执行,属于同一block的所有wrap会被调度到同一核,达到高带宽低延迟。
注意:当程序中同一个block中的thread相互依赖时(如存在barrier),THREADS_PER_BLK不应该超过硬件的warp个数*32。