
November
21st,
2018


深度强化学习
为什么要结合深度学习
以前强化学习的流程是观察 => 状态 => 决策,利用深度学习可以达到end-to-end,即观察 => 决策。这样可以:
- 避免人为刻画一些难以表述的状态;
- 将多步抽样变为单步抽象,减小抽象出错的概率。
实际中的问题
- reward函数难以表述,用逆增强学习:从例子中学习reward函数
- 没有时间、数据来学新的目标,用迁移学习,使用以前经验加速
- 抛开标签,对学习加一些较弱的约束:
- 行为克隆,逆增强学习会观察行为并试图理解真实意图,从而构建reward函数
- 观察世界,而非不断地试错
- 迁移学习,从其他任务中学习;元学习,利用过去经验弄清如何学得更快
序列决策问题
状态序列$s_t$具有马尔可夫性,而观测序列$o_t$没有。
模仿学习(imitation learning)
定义
- 记录$(s_t, o_t)$序列,利用监督学习决策$\pi_{\theta}(a_t|o_t)$,例如无人驾驶,记录图片-方向盘。
- 本质上是将序列决策问题简化为监督学习
缺点
- 无法获得足够多的数据,泛化性差
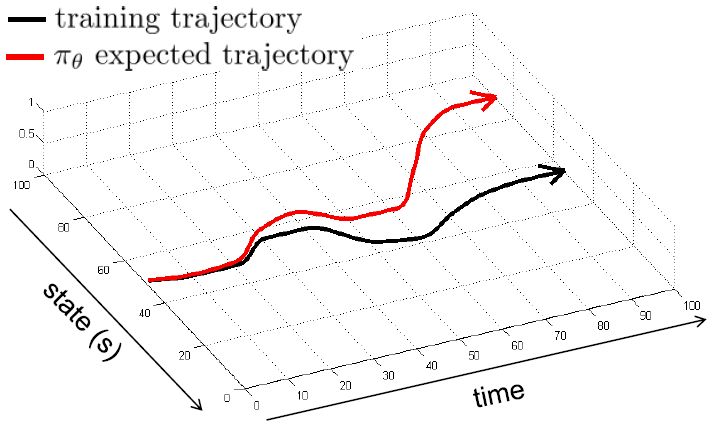
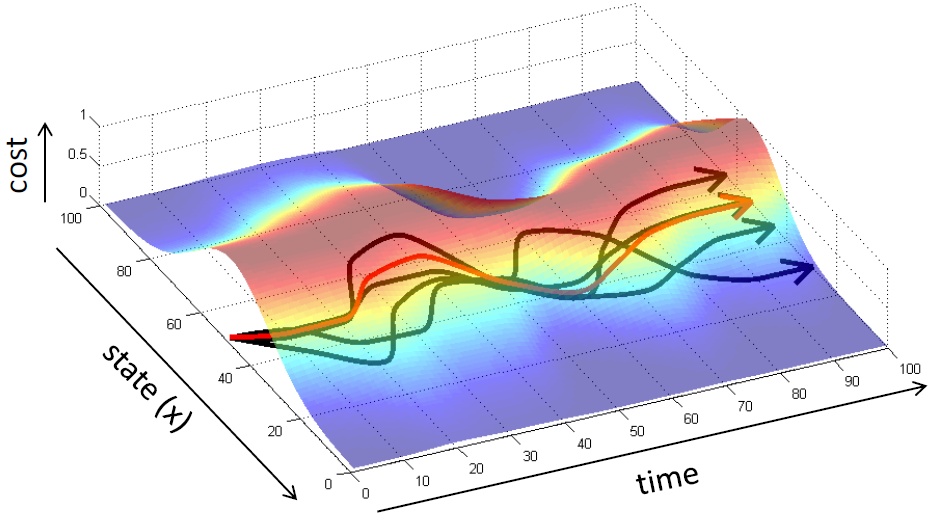
- 即便数据足够,在序列学习中,随着时间增加,轨迹误差会累加。(本质上是由于模仿学习忽略了序列问题中的前后相关性???)
解决
多采数据,限制轨迹偏离。例如无人驾驶中多个摄像头,中间摄像头作为标准,左右摄像头作为稳定控制器,对漂移做出补偿。
引申:DAgger算法
对于轨迹分布$p(\tau)$,其中轨迹$\tau:=(s_1,a_1,…s_T,a_T)$。训练数据符合特定分布$p_{data}(o_t)$,实际轨迹为$p_{\pi_{\theta}}(o_t)$,需要通过域转移(domain shift)来使得二者相等。
用$p_{\pi_{\theta}}(o_t)$去接近$p_{data}(o_t)$很难,于是反过来用$p_{data}(o_t)$去接近$p_{\pi_{\theta}}(o_t)$,即用策略$\pi_\theta(\mathbf{a}_t|\mathbf{o}_t)$来收集新数据。这是DAgger算法的基本思路:
- 从人工数据集$D$训练出策略$p_{\pi_{\theta}}(o_t)$
- 运行策略$p_{\pi_{\theta}}(o_t)$获得新数据集$D_{\pi}$(电脑控制汽车行驶,并收集图片)
- 人工对数据集进行标注,得到新的$(o_t,a_t)$(注:此处为人工生成$a_t$,而非机器生成$a_t$,相当于人对机器进行纠正)
- 合并数据集$\mathcal{D}\leftarrow\mathcal{D}\cup\mathcal{D}_{\pi}$
算法可以理解为“向老师请教怎么学习”,而不是单纯的填鸭式教育。DAgger算法存在的问题是第三步人工标注需要耗费时间,但这是必不可少的,除非算法本身模仿得很精确。通常我们不能很好地学习专家行为,有两个理由:
- 模型的前提是马尔可夫性,但专家行为不一定满足。通常会将多帧数据以RNN形式进行处理。
- 多峰(Multimodal)效应。在无人驾驶中如果碰到障碍物,会选择向左或向右。如果采用单峰的高斯分布,结果会被“平均”,显然不合理;如果采用离散概率分布,可能会离散得过细。这类问题的解决办法有:
- 混合高斯分布。简单,面对高维数据会失效
- 隐性密度模型(Implicit Density Model)。很难训练
- 自回归离散化(Autoregressive Discretization)。对维度一离散,抽样后离散成二维,依次类推。
其他应用领域
- 带有结构预测的问题:如问答系统
- 逆增强学习
总结
- 强化学习的数学描述为序列决策问题;
- 模仿学习相当于将序列决策问题简化为监督学习,因此会丢失序列前后关联性。
- 存在问题:轨迹漂移,训练数据得到的轨迹分布与运行策略得到的轨迹分布不一致。
- 解决:1. 增加稳定器;2. DAgger算法(利用新策略采样数据加入原数据集)
- 缺陷:1. 丢失马尔可夫性,除非利用RNN加入之前的观测;2. 实际问题可能是多峰问题,用高斯分布拟合就会出问题。
- 本质问题:无法利用过去知识形成经验来达到自主学习