
March
5th,
2018

基础
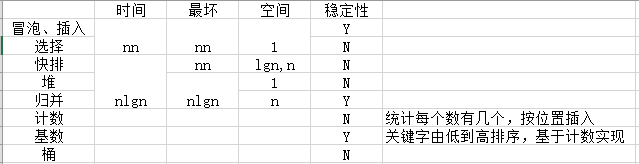
排序
stl sort:
- 总体使用快排,而不是堆:大量局部性排序,缓存命中率高
- 长度减少时,使用插入排序:基本有序时,插入复杂度
O(n) - 递归过深时
>2log(n),使用堆排序 - 只对右序列递归调用
- 三点中值选枢纽
B树,B+树
- 限制树高,多叉平衡树
- 区别:
- B+树中间节点只包含索引关键字,叶子节点包含所有信息 => 容纳更多索引
- 叶子节点通过指针相连 => 扫描简单,不需要遍历树
AVL、红黑树
- AVL:左右子树高度差小于等于1。
- 红黑树:根和叶节点为B;R的子节点为B;任意节点到叶节点路径中B相同。
- 比较
- 插入时,性能相同
- 删除时,红黑O(1),AVL O(lgn)
- AVL更强调平衡,插入删除时更多旋转,查找效率高。
Huffman
- Huffman树
- 定义:带权路径长度最小的二叉树
- 生成:选择最小权重的点作为左右节点
- Huffman编码
- 定义:前缀码,一个字符的编码不是另一个字符编码的前缀
- 生成:构建Hoffman树,左子树为0,右子树为1
海量数据处理
- hash映射,hashmap统计,堆\快速\归并排序
- bitmap/bloom filter
- Trie树,倒排索引(内容 -> ID,适合搜索系统)
Bloom滤波
- bitmap的复杂度与最大元素相关。
- 通过允许一定的错误率来减少内存使用。
- 做法:用k个哈希函数将值映射到bitmap中k个位置;使用时,如果某个值映射的k个位置均为1,表示该值存在。
- 不允许删除(把bitmap每一位扩展成count位,则支持删除)
- 错误率最小时,
k=(ln2)*m/n,n个数,m为bitmap
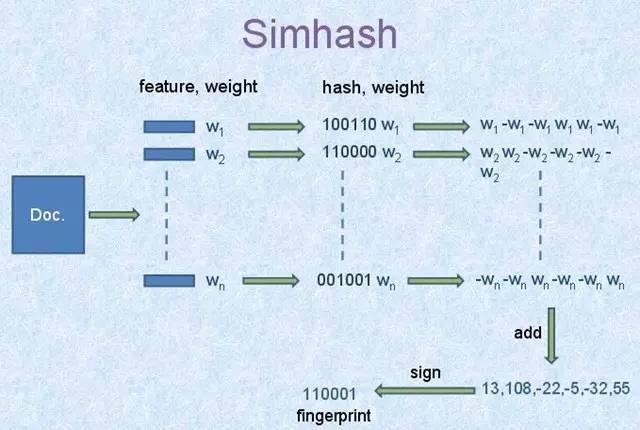
Simhash
- 总体思路:将一个文档转换成一个64位的特征字,然后判断特征字的距离是不是小于n(根据经验这个n一般取值为3),就可以判断两个文档是否相似。
- 特点:局部敏感哈希(改变字符串,结果hashcode中只有部分会改变)
- 大数据hash code比较:根据抽屉原理,将hashcode分成n+1份,其中一份必定完全相同,候选结果减少了
2^16,节省存储空间
算法
快排
int partition(vector<int>& v, int l, int r, int num) {
int i = l-1, j = l;
while (j < r-1) {
if (v[j] < num) {
swap(v[i + 1], v[j]);
i++, j++;
}
else {
j++;
}
}
swap(v[i + 1], v[j]);
return i + 1;
}
void quick_sort(vector<int>& v, int l, int r) {
if (l + 1 >= r)
return;
int m = partition(v, l, r, v[r - 1]);
quick_sort(v, l, m);
quick_sort(v, m + 1, r);
}
堆排序
void max_heapify(vector<int>& v, int i, int heap_size) {
int l = 2 * i + 1;
int r = 2 * i + 2;
int largest;
if (l<heap_size && v[l]>v[i])
largest = l;
else
largest = i;
if (r<heap_size && v[r]>v[largest])
largest = r;
if (largest != i) {
swap(v[i], v[largest]);
max_heapify(v, largest, heap_size);
}
}
void heap_sort(vector<int>& v) {
int heap_size = v.size();
for (int i = (v.size() - 1) / 2; i >= 0; i--)
max_heapify(v, i, heap_size);
for (int i = v.size() - 1; i >= 1; i--) {
swap(v[0], v[i]);
heap_size -= 1;
max_heapify(v, 0, heap_size);
}
}
KMP
void cal_next(string& ptr, vector<int>& arr) {
arr[0] = -1;
int k = -1;
for (int i = 1; i < ptr.size(); i++) {
while (k > -1 && ptr[k + 1] != ptr[i])
k = arr[k];
if (ptr[k + 1] == ptr[i])
k++;
arr[i] = k;
}
}
int KMP(string& str, string& ptr) {
int k = -1, i;
vector<int> arr(ptr.size(), 0);
cal_next(ptr, arr);
for (i = 0; i < str.size(); i++) {
while (k > -1 && ptr[k + 1] != str[i])
k = arr[k];
if (ptr[k + 1] == str[i])
k++;
}
if (k == ptr.size() - 1)
return i - k - 1;
return -1;
}
树相关
二叉搜索树->双向链表
TreeNode* Convert(TreeNode* root){
if(root == nullptr)
return nullptr;
if(root->left == nullptr && root->right == nullptr)
return root;
TreeNode* left = Convert(root->left);
TreeNode* p = left;
while(p && p->right)
p = p->right;
if(left){
p->right = root;
root->left = p;
}
TreeNode* right = Convert(root->right);
if(right){
root->right = right;
right->left = root;
}
return left?left:root;
}
中序遍历
- 栈实现
stack<Node*> s; void inorderTraversal(Node* root){ if(root == nullptr) return; Node* cur = root; while(cur || !s.empty()){ if(cur){ s.push(cur); cur = cur->left; }else{ cur = s.top(); s.pop(); // cur->val; cur = cur->right; } } } - morris
void inorderTraversal(Node* root){ if(root == nullptr) return; Node* cur = root; while(cur){ if(cur->left){ Node* pre = cur->left; while(pre->right && pre->right!=cur) pre = pre->right; if(pre->right == nullptr){ pre->right = cur; cur = cur->left; }else{ pre->right = nullptr; cur = cur->right; } }else{ cur = cur->right; } } }
其他
最长递增子序列
leetcode 300,O(nlogn),[10, 9, 2, 5, 3, 7, 101, 18]->4
最长递增子序列个数
- len[k+1] = len[i]+1, num[i]<num[k+1]
- cnt[k+1] = sum(cnt[i]), num[i]<num[k+1], len[k+1]=len[i]+1
最大子数组
最长连续序列
leetcode 128,O(n),[100, 4, 200, 1, 3, 2]->4
unordered_map<int, int> m;
int longestConsecutive(vector<int>& nums) {
if(nums.size() == 0)
return 0;
int res = 0;
for(int i=0; i<nums.size(); i++){
int temp = nums[i];
int left=0, right=0;
if(m.find(temp)==m.end()){
if(m.find(temp-1) != m.end())
left = m.find(temp-1)->second;
if(m.find(temp+1) != m.end())
right = m.find(temp+1)->second;
int sum = left+right+1;
m[temp]=sum;
res = max(res, sum);
m[temp-left]=sum;
m[temp+right]=sum;
}
}
return res;
}
LRU、LFU
- LRU cacheleetcode 146
- list
,`O(1)`时间交换, - map:key->iter,
O(1)时间访问
- list
- LFU cacheleetcode 460
- map1:freq->list
,多段双向链表 - map2:key->(value,freq)
- map3:key->iter
- map1:freq->list
回文数
- 最长回文子串
- 最长回文子序列
s[i] == s[j] ==> dp[i][j] = max(dp[i+1][j], dp[i][j-1], dp[i+1][j-1]+2)s[i] != s[j] ==> dp[i][j] = max(dp[i+1][j], dp[i][j-1], dp[i+1][j-1])
- 回文子序列个数
aba => 5s[i]!=s[j] ==> dp[i][j] = dp[i+1][j] + dp[i][j-1] - dp[i+1][j-1]s[i]==s[j] ==> dp[i][j] = dp[i+1][j] + dp[i][j-1] - dp[i+1][j-1] + dp[i+1][j-1] + 1动态规划
- house robber 1leetcode 198:不能连续偷两家
- rob[i]=not[i-1]+nums[i]
- not[i]=max(rob[i-1],not[i-1])
- house robber 2leetcode 213:环状
- =max(rob[0,n-2],rob[1,n-1])