
January
20th,
2018


rcnn
- selective search选择proposal,并修正大小,依次通过CNN(重复计算大)
- 先进行SVM分类,然后bounding box回归
fast-rcnn
- 图片通过一次网络,在最后一层卷积层提取proposal,通过roi-pooling
- 分类与回归同时进行,做成multi-task
faster-rcnn
- RPN网络(用网络生成anchor来回归bounding-box。anchor与ground-truth比较重叠面积,生成正类与负类,正负比设为1:3)
- RPN网络与分类回归共享卷积层
- 依然先提取proposal,区分前景背景,后对前景分类与回归,比较慢
- 边框回归:x表示平移,w表示缩放(缩放>0,用e指数表示);当IOU较大时,$ln(1+x)=x$,近似认为是线性变换。
YOLO
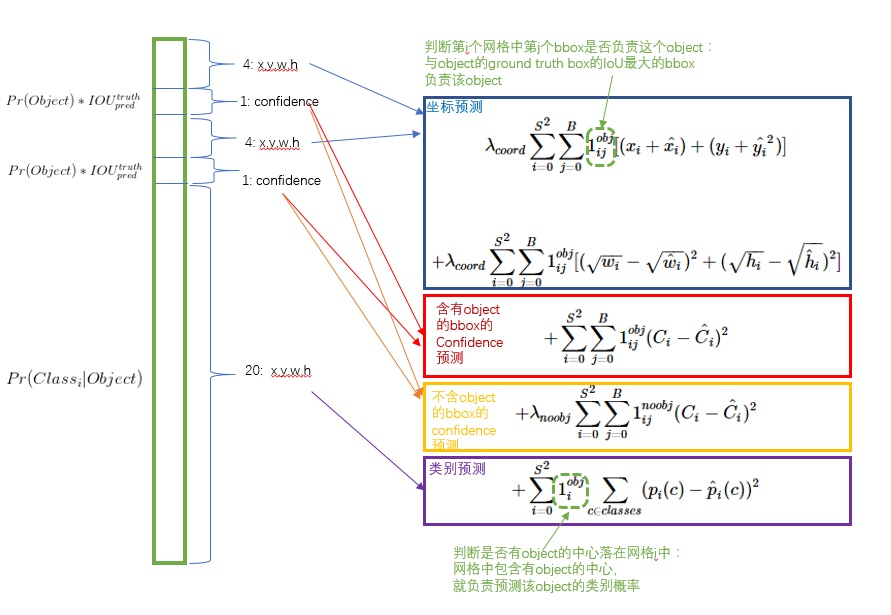
,整幅图片分成$S*S$个网格,B表示bounding-box信息,包括$(x_{center},y_{center})$,w,h,confidence,$x_{center}$与$y_{center}$相对网格归一化,w,h相对图片归一化,confidence表示置信度(是否是物体+IOU),C表示类别数。
- 相当于1个anchor的faster-rcnn,并且前景-背景与类别同时计算。
- 测试时每个格子只能得到一个结果,不适合大量小物体。(而faster-rcnn可以设置anchor大小,不存在这类问题)
- 不适合奇怪形状的物体。
- 最后两层fc 丢失了位置信息,YOLO2进行了改进
- 损失函数为MSE(1、class大多为0,应该减少权重;2、小物体回归时不准确,用sqrt,并不能完全解决)
- 层次分类:生成word-tree,在每一层上扩增数据集,达到局部平衡
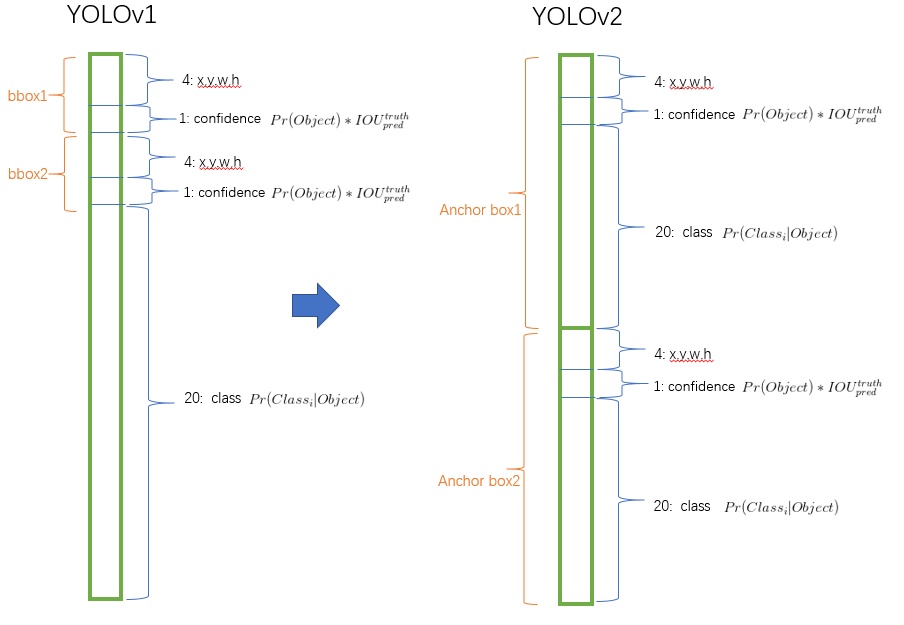
YOLO2
- 预测类别与空间位置解耦(与faster-rcnn一致)
- 每个格子预测5个结果(对ground-truth聚类得到的结果)
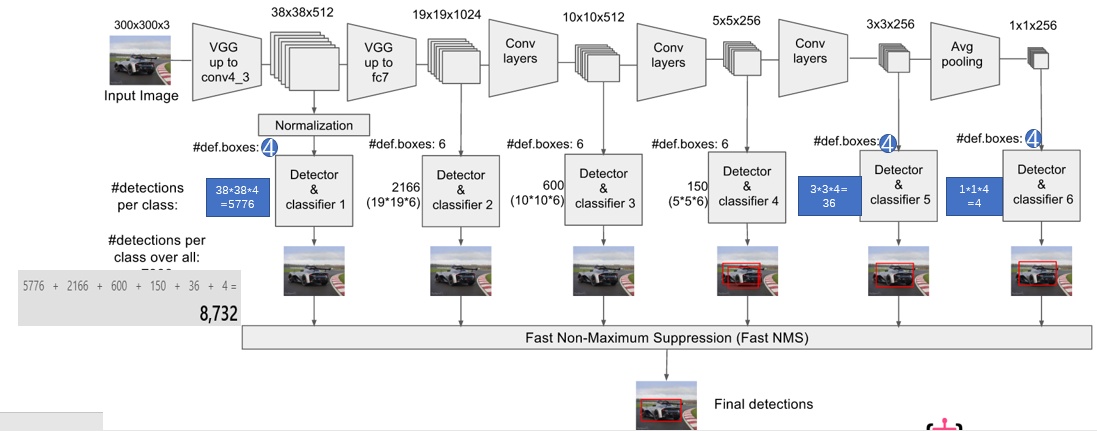
SSD
- 多尺度划分格子,生成
- 训练策略,loss函数与faster-rcnn一致
- 不适合小物体(大物体对应多个anchor,小物体对应一个anchor,得不到充分训练)
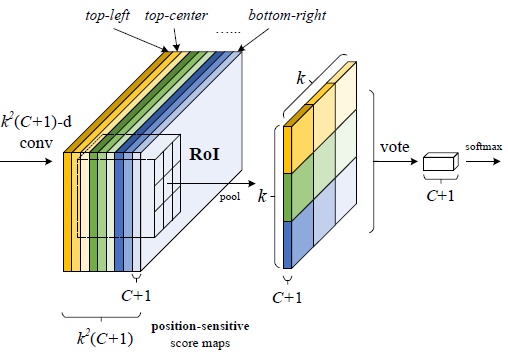
R-FCN
- conv-roi-fc:fc层丢失了位置信息
- conv-roi-conv-fc:roi之后卷积,计算量增大
- conv-position_roi:将位置信息融入卷积层,每个score map都是只属于“一个类别的一个部位”,依据位置pooling
FPN
SSD的每一层feature单独提取,而FPN对后来的feature进行上采样,并且与前面的feature进行融合。
RetinaNet
- 针对一阶段检测
- focal loss $FL(p_t)=-\alpha_t(1-p_t)^{\gamma}log(p_t)$,其中$p_t=p(y=1),1-p(y=other)$,$\alpha_t$类似
- 正负样本不平衡,$\alpha_t$
- 难易样本不平衡(不能丢弃简单负样本,因为它们占了大多数),$\gamma$越大,简单负样本比重越小
mask-RCNN
- 额外加一个分支输出分割mask,对每个像素、每一类设置sigmoid损失输出
- RoIAlign:1、除法不取整;2、每个格子的值由4个内部点线性插值得到