
Table of Contents
1. 常见类型
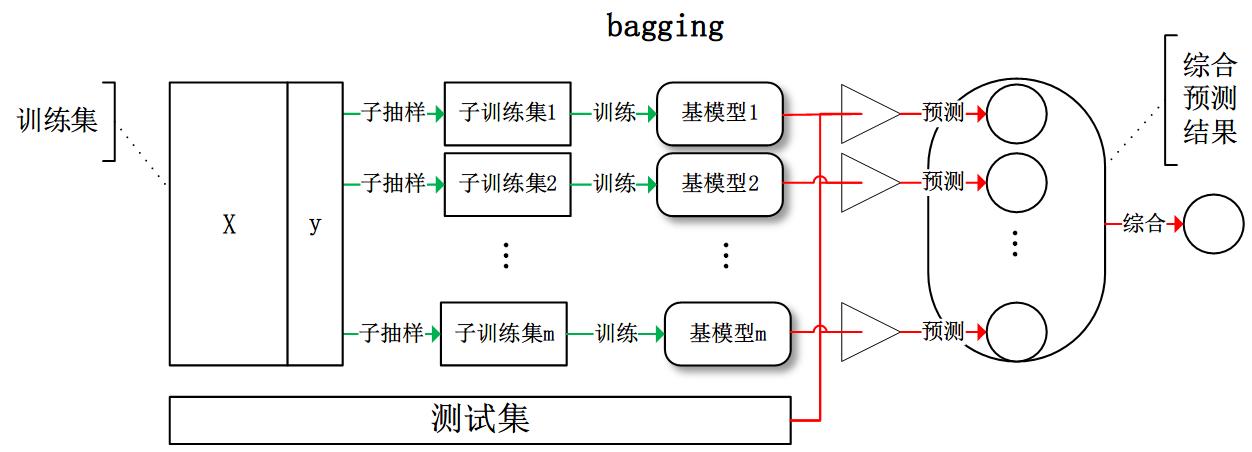
Bagging
从训练集中进行子抽样组成每个基模型所需要的子训练集,对所有基模型预测的结果进行综合产生最终的预测结果。
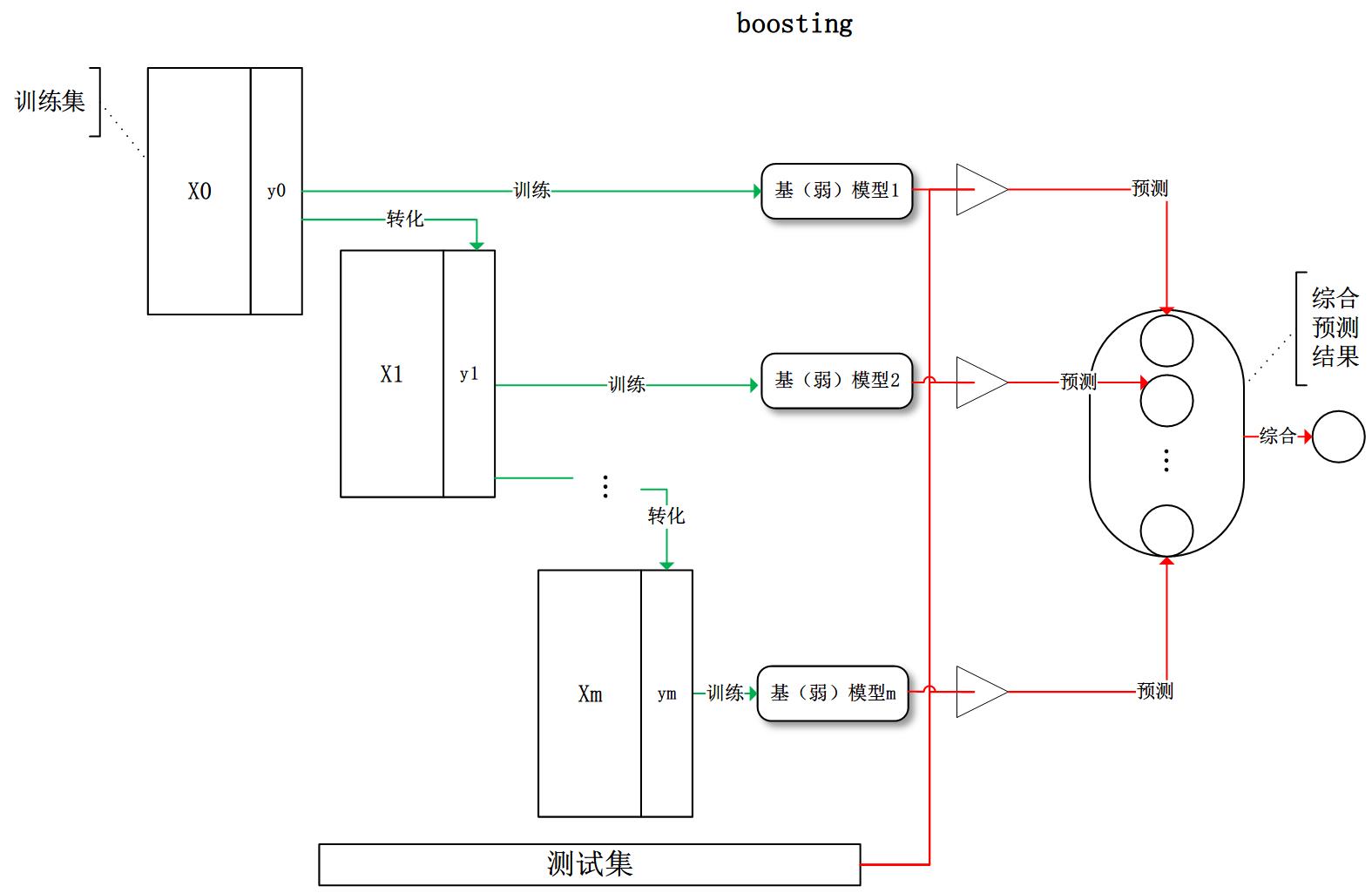
Boosting
训练过程为阶梯状,基模型按次序一一进行训练(实现上可以做到并行),基模型的训练集按照某种策略每次都进行一定的转化。对所有基模型预测的结果进行线性综合产生最终的预测结果。
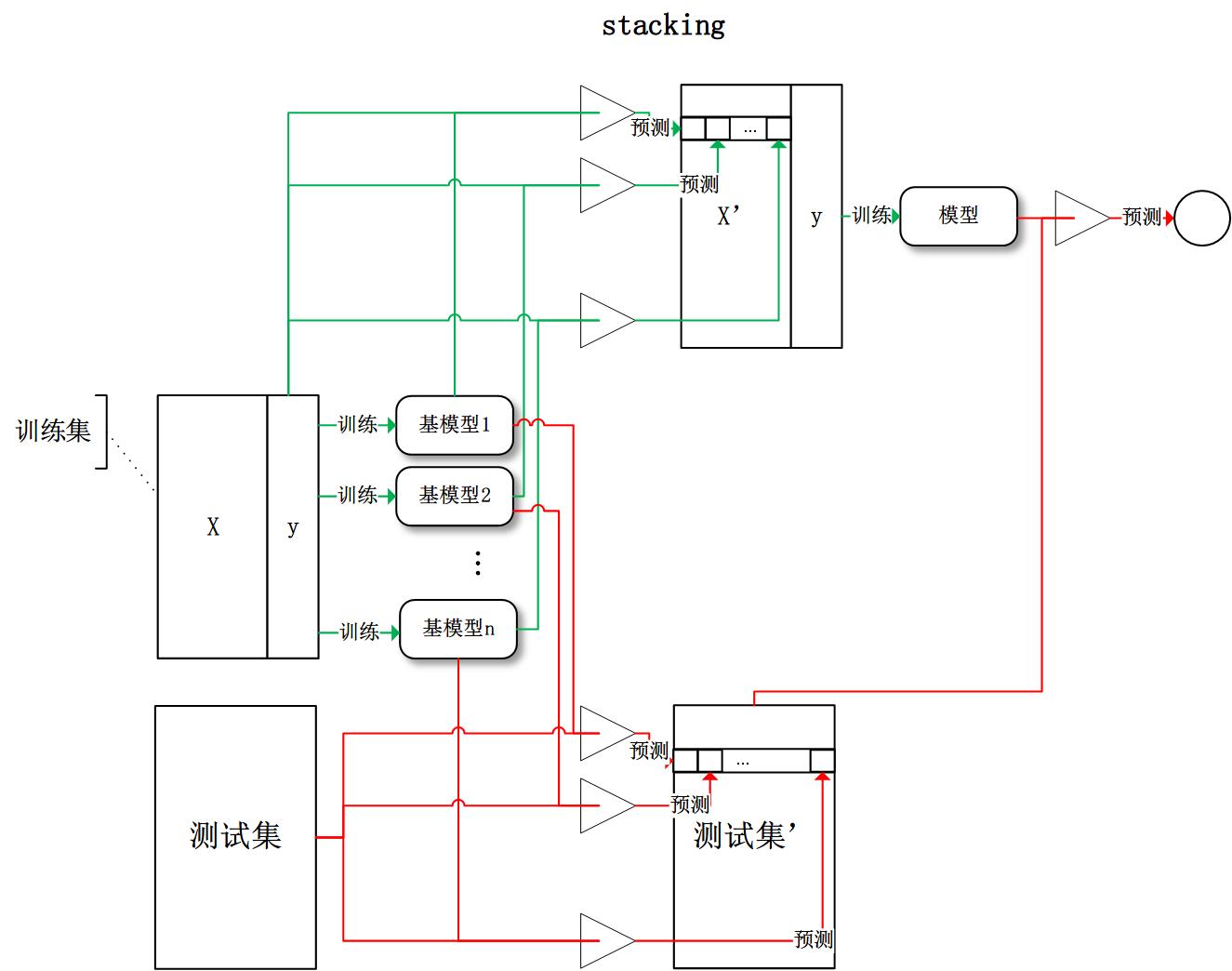
Stacking
将训练好的所有基模型对训练基进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测。
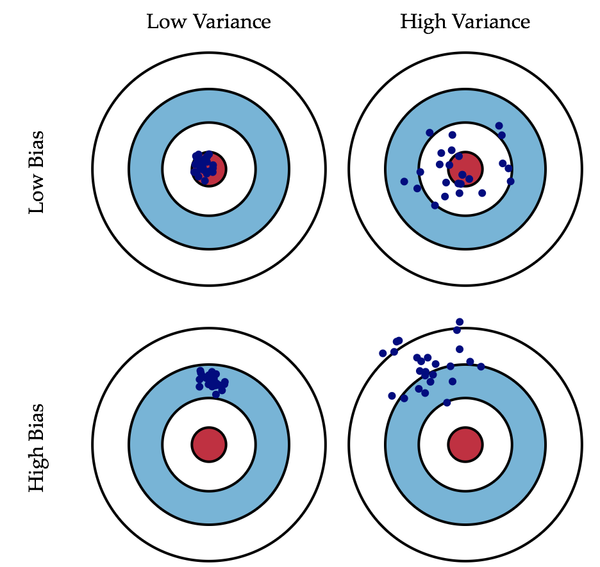
2. 偏差和方差
偏差(bias)描述的是预测值和真实值之间的差异,方差(variance)描述距的是预测值作为随机变量的离散程度。
设样本容量为n的训练集为随机变量的集合(X1, X2, …, Xn),那么模型是以这些随机变量为输入的随机变量函数(其本身仍然是随机变量):F(X1, X2, …, Xn)。抽样的随机性带来了模型的随机性。
在bagging和boosting框架中,通过计算基模型的期望和方差,我们可以得到模型整体的期望和方差。为了简化模型,我们假设基模型的权重、方差及两两间的相关系数相等。由于bagging和boosting的基模型都是线性组成的,那么有:
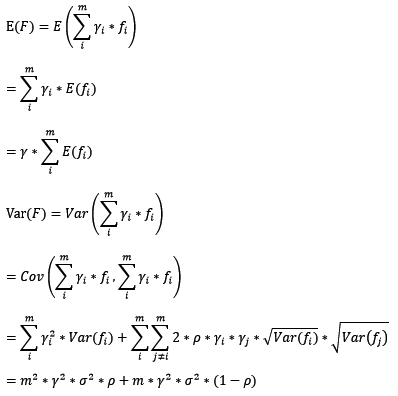
Bagging的偏差和方差
对于bagging来说,每个基模型的权重等于1/m且期望近似相等(子训练集都是从原训练集中进行子抽样),故我们可以进一步化简得到:
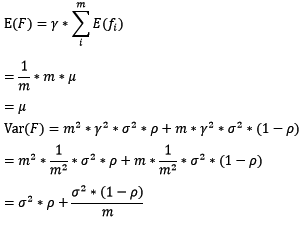
整体模型的期望近似于基模型的期望,这也就意味着整体模型的偏差和基模型的偏差近似。同时,整体模型的方差小于等于基模型的方差(当相关性为1时取等号),随着基模型数(m)的增多,整体模型的方差减少,从而防止过拟合的能力增强,模型的准确度得到提高。但是,模型的准确度一定会无限逼近于1吗?并不一定,当基模型数增加到一定程度时,方差公式第二项的改变对整体方差的作用很小,防止过拟合的能力达到极限,这便是准确度的极限了。另外,在此我们还知道了为什么bagging中的基模型一定要为强模型,否则就会导致整体模型的偏差度低,即准确度低。
Boosting的偏差和方差
对于boosting来说,基模型的训练集抽样是强相关的,那么模型的相关系数近似等于1,故我们也可以针对boosting化简公式为:
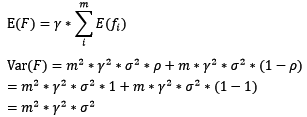
若基模型不是弱模型,其方差相对较大,这将导致整体模型的方差很大,即无法达到防止过拟合的效果。因此,boosting框架中的基模型必须为弱模型。
基于boosting框架的Gradient Tree Boosting模型中基模型也为树模型,同Random Forrest,我们也可以对特征进行随机抽样来使基模型间的相关性降低,从而达到减少方差的效果。
参考资料
