
网络结构
squeeze-net
基本单元:fire-module。每个fire-module代替原来的一层卷积层(或几层) 如:
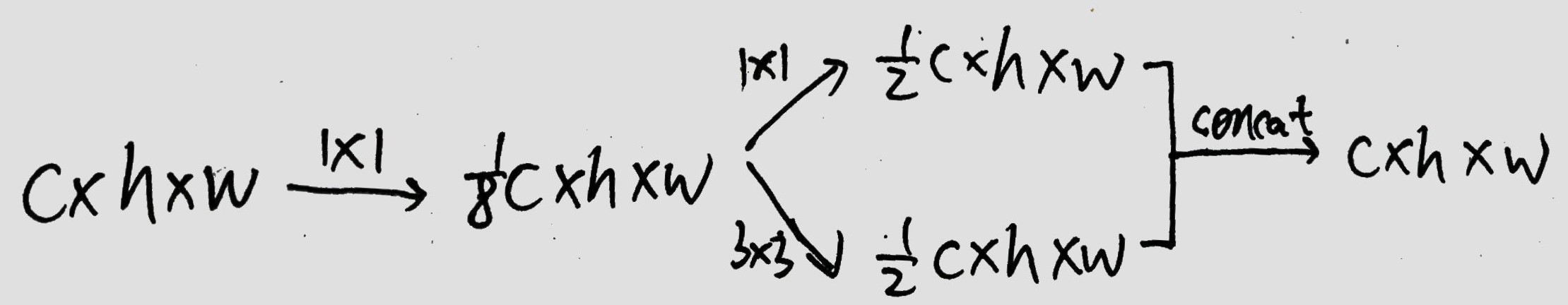
with tf.variable_scope("fire4"):
n = Conv2d(n, 32, (1, 1), (1, 1), tf.nn.relu, 'SAME', name='squeeze1x1')
n1 = Conv2d(n, 128, (1, 1), (1, 1), tf.nn.relu, 'SAME', name='expand1x1')
n2 = Conv2d(n, 128, (3, 3), (1, 1), tf.nn.relu, 'SAME', name='expand3x3')
n = ConcatLayer([n1, n2], -1, name='concat')
with tf.variable_scope("fire5"):
n = Conv2d(n, 32, (1, 1), (1, 1), tf.nn.relu, 'SAME', name='squeeze1x1')
n1 = Conv2d(n, 128, (1, 1), (1, 1), tf.nn.relu, 'SAME', name='expand1x1')
n2 = Conv2d(n, 128, (3, 3), (1, 1), tf.nn.relu, 'SAME', name='expand3x3')
n = ConcatLayer([n1, n2], -1, name='concat')
n = MaxPool2d(n, (3, 3), (2, 2), 'VALID', name='max')
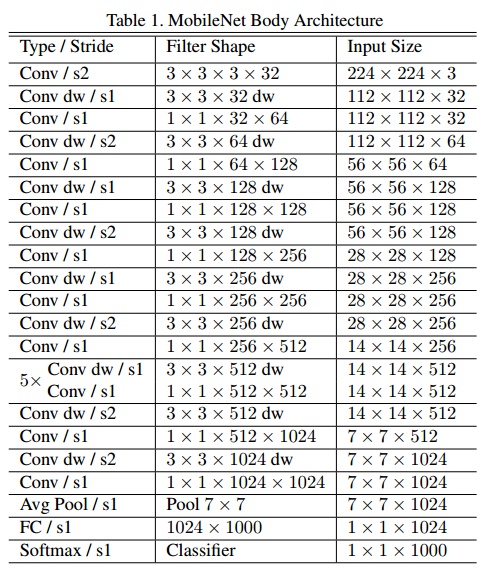
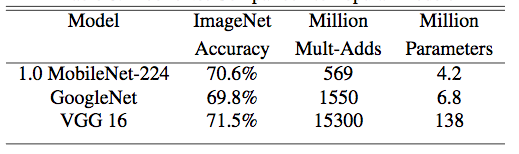
MobileNet
v1
- prototxt
- 卷积层变化
- 原始卷积:$H\cdot W\cdot M \to H\cdot W\cdot N$,卷积核$k\cdot k\cdot M\cdot N$,计算量$k\cdot k\cdot M\cdot N\cdot H\cdot W$
- depthwise:$H\cdot W\cdot M \to H\cdot W\cdot M$,卷积核$k\cdot k\cdot 1\cdot 1$,计算量$k\cdot k\cdot M\cdot H\cdot W$
- pointwise:$H\cdot W\cdot M \to H\cdot W\cdot N$,卷积核$1\cdot 1\cdot M\cdot N$,计算量$M\cdot N\cdot H\cdot W$
- 基本单元对比
- conv-BN-ReLU
- conv_DW-BN-ReLU-conv_PW-BN-ReLU
- 参数
- 控制通道数量$\alpha=0.25,0.5,0.75,1$
- 控制特征图的宽和高$\rho=128,160,192,224$
def depthwise_conv_block(n, n_filter, strides=(1, 1), is_train=False, name="depth_block"): with tf.variable_scope(name): n = DepthwiseConv2d(n, (3, 3), strides, b_init=None, name='depthwise') n = BatchNormLayer(n, act=tf.nn.relu6, is_train=is_train, name='batchnorm1') n = Conv2d(n, n_filter, (1, 1), (1, 1), b_init=None, name='conv') n = BatchNormLayer(n, act=tf.nn.relu6, is_train=is_train, name='batchnorm2') return n
v2
- prototxt
- v1与v2对比
- v1:conv_DW-ReLU-conv_PW-ReLU
- v2:conv_PW-ReLU-conv_DW-ReLU-conv_PW-Linear
- v2在开头加入PW卷积,这是因为DW卷积无法改变通道数,可以使用PW升维度,然后再高危通道使用DW继续工作。
- v2在结尾去掉激活函数。作者认为激活函数在高维空间能增加非线性,在低维空间则会破坏特征。

- v2与ResNet对比
- DW卷积与标准卷积
- 从通道数看,ResNet 为沙漏形,v2为纺锤形

ShuffleNet???
二值化
Binary-Net
论文(XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks),对alexnet有效果,对googlenet、resnet效果不佳。
Binary-Weight-Networks
这一部分只考虑将权重二值化。将权重用二值表示,即处理后$W\in\lbrace -1,1\rbrace$。这个替代过程贯穿整个forward和backward过程,但是在更新参数时候还是采用原来的权重W,主要是因为更新参数需要的精度比较高。
我们希望将权重进行替换$W\approx\alpha B$,其中$\alpha$为尺度参数,$B$为二值权重,所有符号均表示某一层某一个卷积核。优化方法为最小化目标函数$J(B,\alpha)=\Vert W-\alpha B\Vert^2$。展开得到
所以最优解$B^* =argmax_B\lbrace W^TB \rbrace=sign(W)$,$\alpha^* = \frac{W^TB^*}{n}=\frac{W^Tsign(W)}{n}=\frac{1}{n}\Vert W \Vert_{\mathit{l1}}$。具体算法如下。注意:正向传播与梯度计算均使用二值权重,而权重更新使用原始权重。

XNOR-Networks
这一部分考虑将权重和输入均二值化。考虑到卷积操作可以看成是两个向量的点乘,因此希望找到一个近似,使得$X^W\approx \beta H^T\alpha B$。优化目标是$\alpha^* ,B^* ,\beta^* ,H^* = argmin\Vert X\odot W-\beta\alpha H\odot B \Vert_2$,其中$\odot$表示向量点乘。最优解与上面类似。
Ternary-Net
类似的,希望找到一种离散方法,使得$W\in\lbrace -1,0,1\rbrace$。将权重进行替换$W\approx\alpha W^T$,其中$\alpha$为尺度参数,$W^T$为二值权重,所有符号均表示某一层某一个卷积核。优化方法为最小化目标函数$J(W^T,\alpha)=\Vert W-\alpha W^T\Vert^2$。具体离散方式为:
其中,假设权值是由正态分布和平均分布组合,可以推出阈值$\delta \approx \frac{0.7}{n}\sum_{i=1}^n \vert W_i \vert$,最优解参数$\alpha^* = \frac{1}{I_{\delta}}\sum_{i \in I_{\delta}}\vert W_i \vert$,$I_{\delta}$表示权重绝对值大于$\delta$的所有权值。结果显示,在ImageNet数据集上比Binary-Net效果好,但依然有明显的准确率下降。
DoReFa-Net
文章对权重量化成n-bit定点数。假设$x=\sum_{m=0}^{M-1}c_m(x)2^m$和$y=\sum_{k=0}^{K-1}c_k(y)2^k$是两个定点数,则点乘可以表示为
其复杂度与x,y的位宽有关。定义量化操作
会将实数$r_i\in [0,1]$量化成k-bit定点数$r_o\in [0,1]$。具体的前向反向算法如下:
这里的操作只是为了让输入在$[0,1]$范围,让输出在$[-1,1]$范围。由于梯度范围更大,因此使用另外一种方式,并加上高斯噪声,如下:
其中,$N(k)=\frac{\sigma}{2^k-1}$,$\sigma \sim Uniform(-0.5,0.5)$。
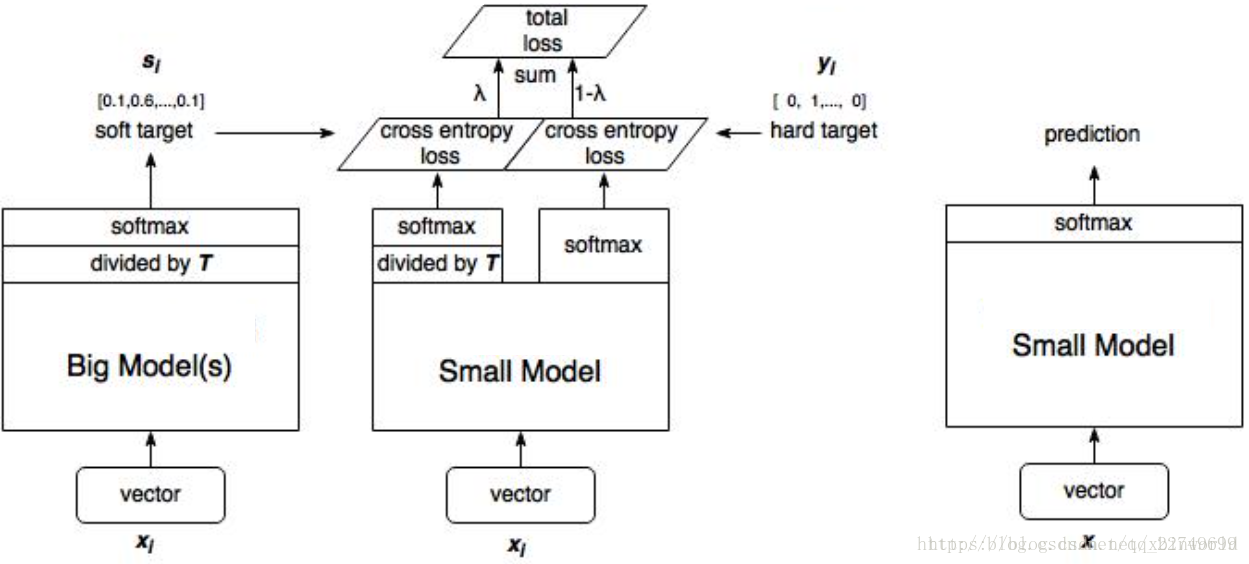
Distilling
论文(Distilling the Knowledge in a Neural Network)提出了一种类似网络迁移的学习算法,通过一个性能好的大网络来教小网络学习,从而达到压缩网络的目的。
soft-target:$q_i = \frac{exp(z_i/T)}{\sum_j exp(z_j/T)}$,当$T>1$时,softmax的输出将更加平滑。具体算法如下:
- 训练大模型:先用hard target,也就是正常的label训练大模型。
- 计算soft target:利用训练好的大模型来计算soft target。
- 训练小模型,在小模型的基础上再加一个额外的soft target的loss function,通过lambda来调节两个loss functions的比重。
- 预测时,将训练好的小模型按常规方式使用。
????
Deep Compression
Deep Compression:Compressing DeepNeural Networks With Pruning, Trained Quantization And Huffman Coding 笔记
只能用于压缩
通道剪枝(channel pruning)
论文1:LASSO-based channel selection
论文(Channel Pruning for Accelerating Very Deep Neural Networks, ICCV2017),对训练好的模型处理以减少inference time。对VGG16能达到两倍压缩,更大的压缩产生轻微准确率下降。核心思路如图:
- 剪枝:对feature map B施加LASSO regression,使得权重稀疏,进行通道剪枝。B剪枝后,前一层和后一层的卷积核也需要对应的剪枝;
- 重建:用最小二乘,使得剪枝后的feature map C与原来的相等。
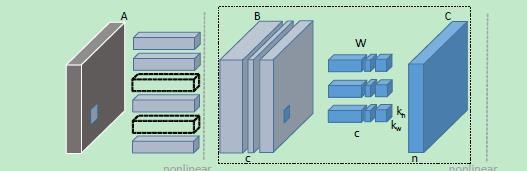
对于输入特征图$X$,输出特征图$Y$,卷积核$W$,剪枝操作$\beta$(对应于01-mask),$c,c’$表示原来和剪枝后输入特征图的通道数,优化公式如下:
其中,F表示Frobenius norm。上式无法直接求解,因此将$\beta$约束加入公式,使用L1约束代替L0约束(有数学证明),对W再施加额外约束,得到:
可以使用迭代方式依次优化$\beta,W$。固定$W$,优化$\beta$有:
固定$\beta$,优化$W$有:
固定$\lambda$,依次迭代至$\Vert\beta\Vert_0$稳定,然后稳步提升$\lambda$,直至满足$\Vert\beta\Vert_0\leqslant c’$。实际中迭代很费时间,因此多次原话$\beta$后再优化一次$W$。对于整个网络,依次对每一层进行操作。对于含分支的网络,如图所示:
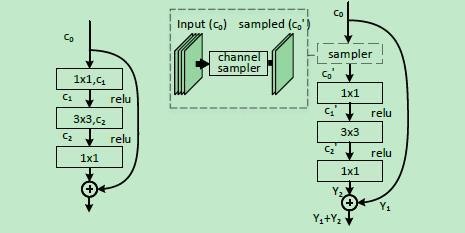
res分支的输入无法进行通道剪枝,因为它和short-cut分支共享,但可以对它进行特征采样得到一个精简的特征进行接下来的卷积。res分支的结尾也无法直接学习,假设res分支输出$Y_2$,short-cut分支输出$Y_1$,res分支需要学$Y_1-Y’_1+Y_2$。
论文2:discrimination-aware
论文(Discrimination-aware Channel Pruning for Deep Neural Networks, NIPS2018)。类似于论文一,在网络中又加了p个discrimination loss,用于鉴别力感知,希望能增强剪枝后所保留特征的鉴别能力。
网络结构如下:
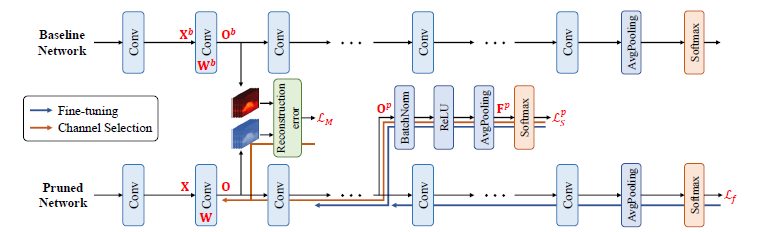
算法如下:算法共$P$个阶段,每次更新$L_{p-1}+1,…,L_p$层。更新时,先得到$L_S^p$,然后通过$L_S^p,L_f$微调裁剪网络参数(为了抑制前几层剪枝带来的累计误差),再根据$L_S^p,L_M$进行通道裁剪。

算法二中,$L(W) = L_M(W)+\lambda L_S^p(W)$,优化目标是
无法直接优化,所以选择贪心选择的方式。首先,从集合$A$之外挑选通道$k=\mathop{\arg\max}_{j\notin A\lbrace \Vert\partial L/\partial W_j\Vert_F \rbrace}$加入集合,然后对选中通道进行优化
其中$W_{A^c}$表示$A$的补集,使用随机梯度进行更新。算法停止条件是$\Vert W\Vert_2>k_l$,由于是凸函数,可以替换成
论文:weight sparsification & dynamic pruning
论文(To prune, or not to prune: exploring the efficacy of pruning for model compression, ICLR2018)。
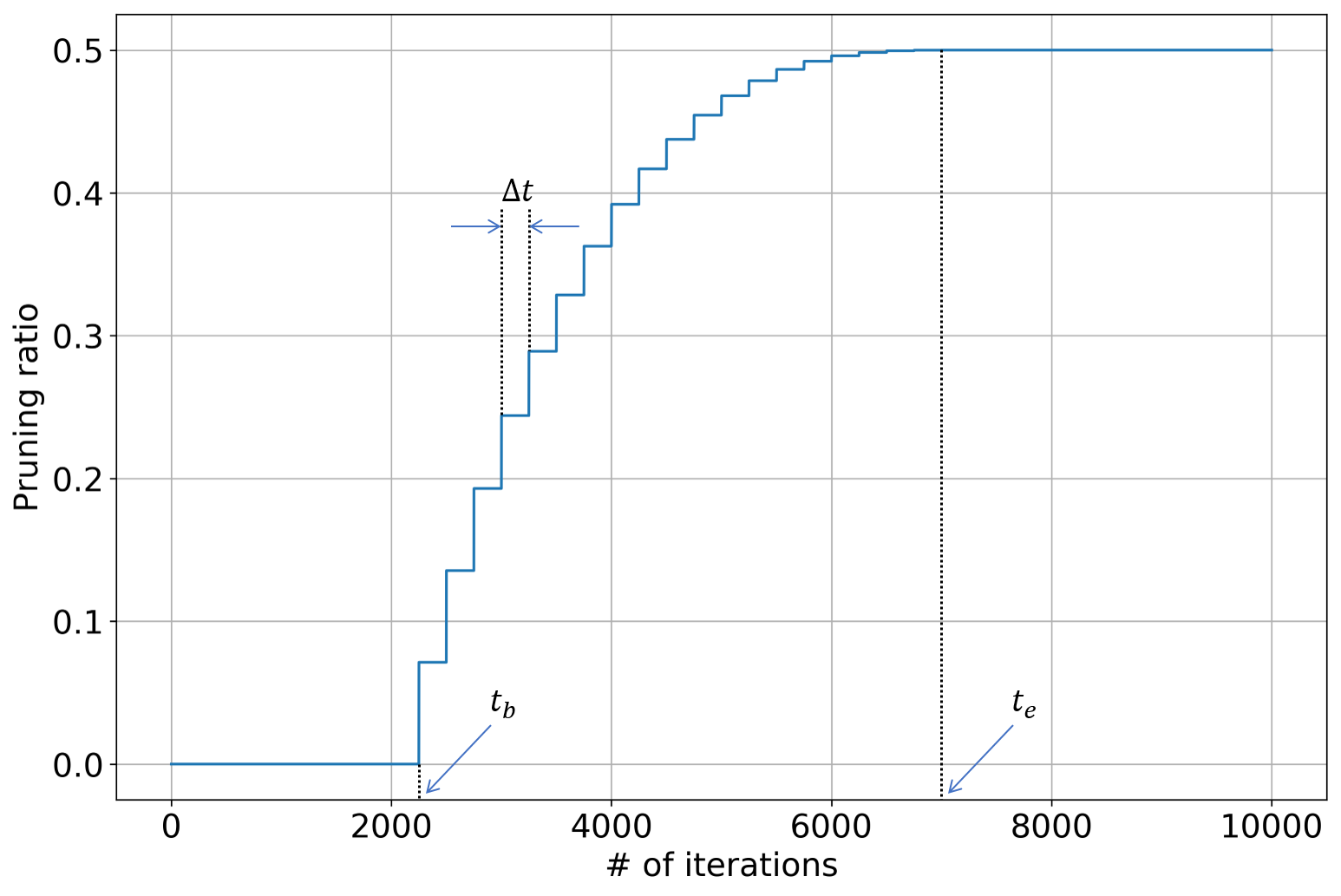
对网络权重施加mask,绝对值最小的一部分权值置为0,不参与正向传播与反向传播。训练时,权重的稀疏度$s_t$会递增,具体定义如下:
网络从头开始训练$t_b$次。然后每训练$\Delta t$次,对mask进行更新,直到到达目标的稀疏性。这样设计函数的目的是为了在训练初始阶段尽快剪枝,然后再放慢剪枝速度。学习率很重要,太快会导致网络每收敛就开始剪枝,太慢导致每次剪枝后网络无法恢复,建议指数下降的学习率。
使用DDPG寻找最佳稀疏度,此处需要预训练的网络帮助retrain:
# ddpg init
for i in range(nb_roll_outs):
for j in range(n_layers):
# 获取当前层的state,action
# retrain:原网络与裁剪后的网络 每一层输出的l2-loss
# finetune裁剪后网络
# 计算loss作为reward
# 得到每一层的最佳稀疏度
论文:uniform Quantization
论文(Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference, CVPR2018)介绍了一种从float32到8-bit定点数的映射,使得推理时只是用8-bit,需要训练好的模型???
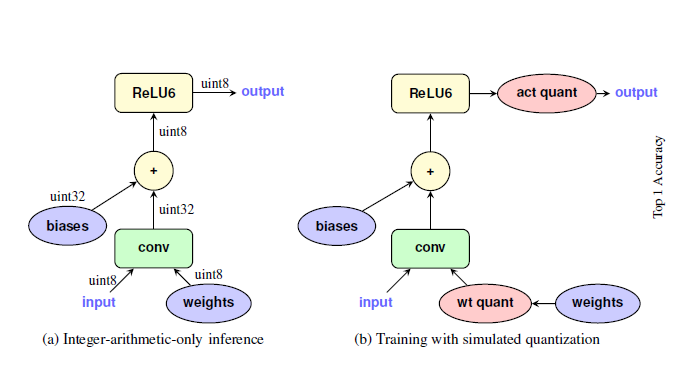
定义一个由实数$r$到整数$q$的映射:
其中$S$表示量化尺度,是一个正实数(后面会将它处理成8-bit);Z是偏移量,是8-bit整数。因此每个实数可以用$\lbrace q,S,Z\rbrace$表示,$S$和$Z$在同一层中是一致的。考虑矩阵相乘$r_3=r_1r_2$,量化后可以得到:
其中$M=\frac{S_1S_2}{S_3}$是唯一的非整数,考虑将它也用8-bit表示。定义$M=2^{-n}M_0$,$M_0$是一个8-bit定点小数,因此整个$M$可以用定点数乘法和移位操作表示。
训练时,在卷积前先对权重进行量化。如果有BN层,可以与conv合并后再量化。量化公式由$\lbrace min,max\rbrace$和$bit-width$两个参数决定。对于卷积层,通常$\lbrace min,max\rbrace$由权重的最大值、最小值决定;对于激活层,$\lbrace min,max\rbrace$由输入的范围决定,并且加上EMA(exponential moving average)保证网络的稳定。
